Autenticación y autorización
Explore y encuentre definiciones claras de glosarios clave relacionados con la autenticación, autorización y gestión de identidad y acceso (IAM). Trabaje con estándares abiertos como OpenID Connect, OAuth 2.0 y SAML y conozca más sobre el sistema de identidad dominicano: Cuenta Única Ciudadana (CUC).
- Acceso sin conexión (Offline access)
- Alcance (Scope)
- Análisis de token (Token introspection)
- API de Gestión (Management API)
- Aprovisionamiento just-in-time (JIT) (Just-in-time provisioning)
- Audiencia (Audience)
- Autenticación (Authentication)
- Autenticación multifactor (Multi-factor authentication, MFA)
- Auth (desambiguación)
- Autorización (Authorization)
- Cifrado Web JSON (JSON Web Encryption, JWE)
- Clave de API (API key)
- Clave de firma (Signing key)
- Clave Web JSON (JSON Web Key, JWK)
- Cliente (Client)
- Concesión de OAuth 2.0 (OAuth 2.0 grant)
- Contraseña de un solo uso (One-time password, OTP)
- Contraseña de un solo uso basada en el tiempo (Time-based one-time password, TOTP)
- Control de acceso (Access control)
- Control de acceso basado en atributos (Attribute-based access control, ABAC)
- Control de acceso basado en roles (Role-based access control, RBAC)
Acceso sin conexión (Offline access)
El acceso sin conexión (Offline access) permite a los clientes obtener nuevos tokens de acceso sin requerir que el usuario vuelva a autenticarse. Es útil para sesiones de larga duración y una mejor experiencia de usuario.
¿Qué es el acceso sin conexión (Offline access)?
El concepto de acceso sin conexión (offline access) puede variar dependiendo del contexto, nos enfocaremos en las especificaciones de OAuth 2.0 y OpenID Connect (OIDC). En este contexto, el acceso sin conexión permite a los clientes obtener nuevos tokens de acceso (access tokens) usando un token de actualización (refresh token) sin requerir que el usuario vuelva a autenticarse. Esta característica es particularmente útil para sesiones de larga duración y una mejor experiencia de usuario.
Vale la pena señalar que OAuth 2.0 no define el término “acceso sin conexión” explícitamente; solo especifica el uso de tokens de actualización para obtener nuevos tokens de acceso. Sin embargo, el término “acceso sin conexión” (junto con el scope offline_access) ha sido ampliamente adoptado en la industria para referirse a esta capacidad, y está oficialmente definido en la especificación OpenID Connect (OIDC) .
¿Cómo funciona el acceso sin conexión (Offline access)?
Para simplificar, usaremos los términos de OAuth 2.0 Solicitud de autorización (Authorization request) y Servidor de autorización (Authorization server) para ilustrar cómo funciona el acceso sin conexión. Sus términos alternativos en OIDC son Solicitud de autenticación (Authentication request) y Proveedor de OpenID (OP) , respectivamente.
Hay dos pasos principales involucrados en usar el acceso sin conexión:
- Solicitar acceso sin conexión: Cuando el Cliente (Client) inicia una autorización (authorization request) al servidor de autorización (authorization server), incluye el scope
offline_accesspara solicitar acceso sin conexión. Este scope indica que el cliente desea obtener un token de actualización junto con el token de acceso.
El soporte para acceso sin conexión puede variar entre diferentes servidores de autorización, y el servidor de autorización puede ignorar el scope offline_access si no lo admite. Por favor, consulta la documentación del servidor de autorización para asegurar la compatibilidad antes de usar este scope.
- Usar el token de actualización: Una vez que la Concesión de OAuth 2.0 (OAuth 2.0 grant) se complete, el cliente debería recibir un token de actualización (refresh token) junto con el token de acceso (access token) . El cliente puede almacenar el token de actualización de manera segura y usarlo para enviar una solicitud de token (token request) al servidor de autorización para obtener un nuevo token de acceso cuando el token de acceso actual expire.
Alcance (Scope)
El alcance (scope) define los permisos que una aplicación solicita de un usuario para acceder a sus recursos protegidos. Es un concepto fundamental en OAuth 2.0 y OIDC (OpenID Connect) que controla el nivel de acceso que una aplicación puede tener a los datos de un usuario.
¿Qué es un alcance (scope)?
En los protocolos OAuth 2.0 y OpenID Connect (OIDC) , un alcance (scope) es un mecanismo para limitar el acceso que una aplicación tiene a los recursos de un usuario. Define los permisos que la aplicación está solicitando del usuario.
Los alcances se representan como cadenas de texto que son definidas por el servidor de autorización (authorization server). Cuando una aplicación solicita acceso a los recursos de un usuario, especifica los alcances que necesita en la solicitud de autorización (authorization request). Luego se le pide al usuario que otorgue o niegue estos permisos durante el proceso de autorización.
¿Por qué usar alcances?
- Control de acceso (access control) granular: Los alcances permiten a las aplicaciones solicitar solo los permisos que necesitan para realizar acciones específicas, reduciendo el riesgo de acceso no autorizado.
- Consentimiento del usuario: Los alcances ayudan a los usuarios a entender qué datos la aplicación accederá y por qué.
- Seguridad: Los alcances ayudan a prevenir que las aplicaciones sobrepasen sus permisos de acceso, mejorando la seguridad de los datos del usuario.
¿Cómo funciona el alcance (scope)?
Cuando una aplicación inicia el proceso de autorización (authorization) de OAuth 2.0 / OIDC, incluye una lista de alcances en la solicitud de autorización (authorization request). El servidor de autorización (authorization server) presenta al usuario una pantalla de consentimiento que lista los alcances solicitados. El usuario puede elegir otorgar o negar acceso a cada alcance. Este proceso se utiliza típicamente cuando la aplicación es una aplicación de terceros que requiere acceso a los recursos del usuario.
Alternativamente, si la aplicación es de confianza para el servidor de autorización (authorization server), es posible que no se le pida al usuario el consentimiento, sino que se realice un consentimiento automático y se otorguen todos los alcances solicitados.
Definición de alcances
Los alcances son típicamente definidos por el proveedor de API. Pueden ser:
- Alcances estándar: Alcances comúnmente utilizados definidos por la especificación de OAuth 2.0, compartidos por diferentes aplicaciones y servicios. Por ejemplo
openid,profile,email. - Alcances personalizados: Específicos para una aplicación o servicio, adaptados a sus requisitos únicos. Por ejemplo
read:orders,write:comments.
¿Dónde se pueden utilizar los alcances en OIDC y gestión de identidades?
Los alcances pueden utilizarse en varios aspectos de OIDC, incluyendo pero no limitándose a:
- Autenticación (Authentication): Los alcances pueden utilizarse para solicitar información específica del usuario durante el proceso de autenticación (authentication). Por ejemplo
profile,email. - Autorización (Authorization): Los alcances pueden utilizarse para solicitar acceso a recursos específicos o realizar acciones específicas. Por ejemplo
read:orders,write:comments. - Consentimiento: Los alcances se presentan al usuario durante la pantalla de consentimiento para informarles de los permisos solicitados por la aplicación.
- Emisión de tokens: Los alcances se incluyen en la respuesta del token para indicar los permisos otorgados a la aplicación.
- Validación de tokens: Los alcances pueden utilizarse para validar los derechos de acceso de la aplicación cuando presenta el token para acceder a recursos protegidos.
- Servidor de recursos (Resource server): Los alcances pueden ser utilizados por el servidor de recursos para aplicar políticas de control de acceso (access control) basadas en los permisos otorgados a la aplicación.
- Perfil del usuario: Los alcances pueden utilizarse para solicitar información adicional del perfil del usuario más allá de los claims básicos.
Mejores prácticas
- Solicitar alcances mínimos: Siempre solicita el conjunto mínimo de alcances necesario para el funcionamiento de tu aplicación. Esto minimiza el riesgo de sobre-permiso y mejora la confianza del usuario.
- Explicar el uso de alcances: Explica claramente a los usuarios por qué se necesita cada alcance. La transparencia ayuda a obtener el consentimiento del usuario.
- Utilizar alcances estándar cuando sea posible: Aprovecha los alcances estándar para asegurar la compatibilidad y reducir la complejidad.
Análisis de token (Token introspection)
El análisis de token (Token introspection) es una extensión de OAuth 2.0 que permite a los clientes consultar el servidor de autorización para validar los tokens de acceso (access tokens) y recuperar metadatos sobre ellos.
¿Qué es el análisis de token (token introspection)?
El análisis de token (Token introspection) es una extensión de OAuth 2.0 definida en RFC 7662 que permite a los clientes consultar el Servidor de autorización (Authorization server) para validar los tokens de acceso (access tokens) y recuperar metadatos sobre ellos. Esta extensión es útil cuando:
- El cliente quiere verificar la validez de un token de acceso (access token) en tiempo real.
- El token de acceso (access token) es opaco (no autónomo) y requiere que el servidor de autorización lo valide.
¿Cómo funciona el análisis de token (token introspection)?
Aquí hay un ejemplo no normativo de una solicitud de análisis de token (token introspection):
POST /introspect HTTP/1.1
Host: authorization-server.example.com
Content-Type: application/x-www-form-urlencoded
token=random-token-value
&token_type_hint=access_token
El parámetro token_type_hint es opcional y debe establecerse en el tipo de token que se está analizando. Si el token de acceso (access token) es válido, el servidor de autorización responde con los metadatos del token:
HTTP/1.1 200 OK
Content-Type: application/json
{
"active": true,
"scope": "read write",
"client_id": "client-id",
"username": "johndoe",
"token_type": "Bearer",
"exp": 1634020800,
"iat": 1634017200
}
Vale la pena señalar que no todos los servidores de autorización (authorization servers) admiten el análisis de token (token introspection) y no todos los tokens son susceptibles de análisis. El Servidor de autorización (Authorization server) puede limitar el uso del análisis de token (token introspection) basándose en varios factores, por ejemplo, algunos servidores de autorización pueden no admitir el análisis de JWTs .
Parámetros clave en una solicitud de análisis de token (token introspection)
Estos son dos parámetros clave en una solicitud de análisis de token (token introspection):
token: El token a analizar.token_type_hint: El tipo de token que se está analizando. Puede seraccess_tokenorefresh_token.
API de Gestión (Management API)
El API de Gestión en el contexto de la gestión de identidad y acceso (IAM) permite la gestión programática de recursos como usuarios, aplicaciones, roles y permisos. Típicamente RESTful, proporciona una capa de abstracción entre el sistema IAM y la interfaz de usuario, permitiendo la automatización, integración y desarrollo de características personalizadas.
¿Qué es el API de Gestión?
La definición de API de Gestión puede variar dependiendo del software o servicio que estés utilizando. En el contexto de la gestión de identidad y acceso (IAM), el API de Gestión generalmente se refiere a un conjunto de APIs que te permiten gestionar programáticamente los recursos relacionados con IAM. Por ejemplo, usuarios, aplicaciones, roles, permisos, organizaciones, etc.
Aunque el nombre no especifica la implementación exacta, el API de Gestión suele ser RESTful, dada su naturaleza de definir precisamente los recursos y las operaciones que se pueden realizar sobre ellos. Dicho esto, cuando ves POST /users, puedes esperar que esta llamada API creará un nuevo usuario.
¿Por qué es importante el API de Gestión?
El API de Gestión crea una capa separada de abstracción sobre el sistema IAM, pero debajo de la interfaz de usuario. Esto permite a los desarrolladores automatizar la gestión de recursos IAM, lo cual puede ser especialmente útil en varios escenarios:
1. Automatización
Como sugiere el nombre, el API de Gestión te permite usar código para gestionar recursos, en lugar de hacer clic manualmente a través de la interfaz de usuario. Esto es particularmente útil cuando tienes un gran número de usuarios, aplicaciones o roles que gestionar. Por ejemplo, puedes escribir un script para importar usuarios de un archivo CSV y asignarles los roles y permisos correctos.
2. Integración
El API de Gestión crea una manera estándar para la comunicación de servicio a servicio (o máquina a máquina). Cuando tienes múltiples servicios que necesitan comunicarse con el sistema IAM, en lugar de implementar integraciones personalizadas para cada servicio, un API de Gestión bien diseñado puede ser utilizado para todos los servicios combinando las llamadas API. Por ejemplo, un servicio que necesita listar todos los usuarios bajo un rol específico puede hacerlo llamando GET /roles/{role_id}/users.
3. Composición y extensión de características
Debido a la variedad de requisitos empresariales, un sistema IAM puede no ser capaz de proporcionar todas las características exactas que necesitas, especialmente cuando se trata de requisitos complejos de control de acceso (access control). El API de Gestión te permite construir características personalizadas sobre el sistema IAM existente sin modificar la plataforma o arquitectura subyacente.
Veamos un ejemplo cotidiano: los usuarios finales necesitan cambiar su dirección de correo electrónico. Diferentes aplicaciones pueden tener diferentes requisitos:
- La App A requiere que el usuario verifique tanto la dirección de correo antigua como la nueva.
- La App B requiere que el usuario verifique la contraseña existente antes de cambiar la dirección de correo.
- La App C requiere que el usuario verifique la contraseña existente y que un administrador apruebe el cambio de correo.
Con el API de Gestión, puedes construir un servicio personalizado que orqueste estos requisitos llamando a las APIs necesarias en el orden correcto. Incluso puedes combinar el API de Gestión con el API de tu servicio para lograr un flujo de trabajo complejo. Tomemos como ejemplo la App C:
- El usuario hace clic en “Cambiar Correo” en la App C, lo que envía una solicitud
POST /email-change-requestsa tu servicio. Este crea una nueva solicitud de cambio de correo y devuelve el identificadorfoo. - La App C muestra un cuadro de diálogo al usuario, pidiéndole que ingrese la contraseña existente.
- El usuario ingresa la contraseña, y la App C envía una solicitud
PATCH /email-change-requests/fooa tu servicio con la contraseña. En segundo plano, tu servicio verifica la contraseña llamando al API de GestiónPOST /users/{user_id}/verify-password. - Si la contraseña es correcta, tu servicio crea un registro de verificación exitosa en la solicitud de cambio de correo
foo. - En el panel de administración, un administrador puede ver las solicitudes de cambio de correo pendientes con
GET /email-change-requests?status=pending. - Si el administrador aprueba la solicitud, el panel de administración envía una solicitud
PATCH /email-change-requests/fooa tu servicio con la aprobación del administrador. - Tu servicio entonces llamará al API de Gestión
PATCH /users/{user_id}para actualizar la dirección de correo del usuario. Si la dirección de correo no puede ser actualizada, el API de Gestión devolverá un error, y tu servicio podrá manejarlo en consecuencia.
Nota que en el ejemplo anterior, nuestros usuarios finales nunca interactúan directamente con el API de Gestión. En cambio, interactúan con la App C, que orquesta las llamadas al API de Gestión en segundo plano para lograr el flujo de trabajo deseado.
¿Cómo debería ser un buen API de Gestión?
- RESTful: Sigue los principios RESTful para hacer el API predecible y fácil de usar.
- Orientado a recursos: Representa recursos como sustantivos y utiliza métodos HTTP para realizar acciones sobre ellos.
- Consistente: Usa convenciones de nomenclatura, manejo de errores y formatos de respuesta coherentes.
- Seguro: Implementa mecanismos adecuados de autenticación (authentication) y autorización para proteger el API.
- Documentado: Proporciona documentación clara y concisa sobre cómo usar el API, incluyendo ejemplos y casos de uso.
- Compatible: Asegura la compatibilidad retroactiva al introducir nuevas versiones del API.
- Completo: Cubre todas las operaciones necesarias para gestionar eficazmente los recursos IAM.
Existen otros aspectos como el rendimiento y la escalabilidad, que están más relacionados con la infraestructura que con el diseño del API en sí. Sin embargo, en la práctica, un buen API de Gestión debería considerar también estos aspectos.
Aprovisionamiento just-in-time (JIT) (Just-in-time provisioning)
El aprovisionamiento just-in-time (JIT) es un proceso de gestión de identidad y acceso (IAM) donde las cuentas de usuario se crean de manera dinámica y automática cuando un usuario intenta acceder a un sistema o aplicación por primera vez. Este enfoque ayuda a agilizar el proceso de incorporación y asegura que las cuentas de usuario solo se creen cuando sea necesario, reduciendo la carga administrativa y mejorando la seguridad.
¿Qué es el aprovisionamiento just-in-time?
Si estás construyendo una aplicación SaaS B2B y deseas admitir funciones de membresía, permitiendo que los miembros se unan fácilmente a tu espacio de trabajo (tenant). Podrías necesitar funciones como las del siguiente cuadro, y el aprovisionamiento just-in-time es una de ellas, ayudando a agilizar el proceso.
| Características | Flujo |
|---|---|
| Invitación iniciada por el admin | Los usuarios pueden recibir una invitación por correo electrónico para unirse a la organización. |
| Creación o importación de usuarios a través de API | Los usuarios pueden usar una cuenta de usuario precreada para unirse a la organización. |
| Aprovisionamiento just-in-time | Los usuarios que inician sesión en la aplicación por primera vez pueden unirse a la organización. |
| Sincronización de Directorio (por ejemplo, SCIM) | Usar la funcionalidad de Sincronización de Directorio del IdP para preaprovisionar usuarios en la aplicación con anticipación. |
El aprovisionamiento just-in-time (JIT) es un proceso utilizado en sistemas de gestión de identidad y acceso para crear cuentas de usuario sobre la marcha a medida que se inician sesión en un sistema por primera vez. En lugar de preaprovisionar cuentas para los usuarios con anticipación, el aprovisionamiento JIT crea y configura las cuentas de usuario necesarias de manera dinámica cuando un usuario realiza una autenticación. El aprovisionamiento just-in-time es una característica popular con sus propias características, como la eficiencia, la no participación administrativa y la membresía automática en la organización, etc.
¿Cuáles son los casos de uso del aprovisionamiento just-in-time?
Estos casos son comunes al construir una aplicación B2B que involucra arquitectura multi-tenant, Enterprise SSO, trabajar con empresas o requerir funciones de incorporación de equipos. Aquí hay algunos escenarios de muestra que tus clientes pueden enfrentar.
Incorporación rápida
Tienes un cliente que experimenta contrataciones frecuentes o un rápido crecimiento, puede usar el aprovisionamiento JIT para configurar rápidamente cuentas de usuario para nuevos empleados. Aquí hay un ejemplo:
Sarah es una nueva empleada en la empresa SuperFantasy, que utiliza Okta como su Proveedor de Identidad Empresarial. El equipo de recursos humanos la agrega como una identidad empresarial en Okta solo una vez. Cuando Sarah usa este correo electrónico para iniciar sesión en una aplicación de productividad de uso corporativo llamada Smartworkspace por primera vez, el sistema crea automáticamente una cuenta y le asigna el rol correcto dentro del espacio de trabajo de la empresa. De esta manera, ni Sarah ni el equipo de recursos humanos de SuperFantasy necesitan pasar por múltiples pasos para la creación de la cuenta y la asignación del rol.
Fusiones, adquisiciones y trabajadores temporales
Tienes un cliente que experimenta fusiones o adquisiciones de otras empresas, el aprovisionamiento JIT puede simplificar el proceso de otorgar acceso a los sistemas de la empresa adquirente para muchos nuevos usuarios. Veamos otro ejemplo,
Peter trabaja para MagicTech, que fue recientemente adquirida por SuperFantasy. MagicTech es una organización más pequeña sin Enterprise SSO, pero también utiliza Smartworkspace, donde Peter ya tiene una cuenta empresarial.
El equipo de recursos humanos puede agregar a Peter en Okta. Cuando Peter inicia sesión en Smartworkspace por primera vez a través de Okta, el sistema vincula automáticamente su cuenta empresarial existente y otorga el acceso apropiado a SuperFantasy.
Los escenarios anteriores son ideales para implementar la función JIT.
¿Es específico de SAML y Enterprise SSO?
El aprovisionamiento just-in-time (JIT) a menudo se asocia con Enterprise SSO en la autenticación SAML, pero no es exclusivo de Lenguaje de marcado para declaraciones de seguridad (Security Assertion Markup Language, SAML) . El aprovisionamiento JIT también se puede usar con otros protocolos de autenticación como OAuth 2.0 y OpenID Connect (OIDC) , y no siempre requiere una configuración de Enterprise SSO .
Por ejemplo, el aprovisionamiento JIT basado en correo electrónico puede agilizar la incorporación de equipos al agregar automáticamente usuarios a un espacio de trabajo según su dominio de correo electrónico. Esto es particularmente útil para organizaciones que carecen del presupuesto y recursos para adquirir y gestionar Enterprise SSO.
La idea fundamental detrás del aprovisionamiento JIT es automatizar la creación o actualización de cuentas de usuario cuando un usuario intenta acceder a un servicio por primera vez, independientemente del protocolo específico utilizado.
¿Se aplica a usuarios nuevos o existentes de la aplicación?
El aprovisionamiento just-in-time (JIT) generalmente se refiere al primer intento de acceso a una aplicación. Sin embargo, diferentes productos perciben esta funcionalidad de manera diferente. Algunos utilizan el aprovisionamiento JIT solo para la creación de identidad y cuentas, mientras que otros también incluyen actualizaciones de cuentas just-in-time, como reprovisionamiento y sincronización de atributos.
Además de la creación automática de usuarios, el aprovisionamiento SAML JIT permite otorgar y revocar membresías de grupos como parte del aprovisionamiento. También puede actualizar usuarios aprovisionados para mantener sus atributos en el almacén del Proveedor de servicios (Service provider, SP) sincronizados con los atributos del almacén del Proveedor de identidad (Identity provider, IdP) .
Si deseas considerar el escenario de inicio de sesión de usuarios existentes subsiguiente, asegúrate de tener un sistema de aprovisionamiento robusto junto con tu sistema JIT. Por ejemplo,
- Resolución de conflictos: Tu sistema debe tener una estrategia para manejar conflictos si ya existe una cuenta con información diferente a la proporcionada por el IdP durante el proceso JIT. Esto puede requerir un control detallado de las políticas de tu organización y la configuración del IdP.
- Registros de auditoría: Es importante mantener registros tanto de las nuevas creaciones de cuentas como de las actualizaciones de cuentas existentes a través de procesos JIT por razones de seguridad y cumplimiento.
- Rendimiento: Aunque el aprovisionamiento JIT ocurre rápidamente, considera el impacto potencial en los tiempos de inicio de sesión, especialmente para usuarios existentes si estás actualizando su información en cada inicio de sesión.
- Consistencia de datos: Asegúrate de que tu proceso de aprovisionamiento JIT mantenga la consistencia de los datos, especialmente al actualizar cuentas de usuario existentes.
¿Cuál es la diferencia entre JIT y SCIM?
SCIM es un protocolo estándar abierto diseñado para simplificar y automatizar la gestión de identidad de usuarios en diferentes sistemas y dominios. Se utiliza comúnmente en escenarios de Sincronización de Directorios.
La principal diferencia entre JIT y SCIM es que JIT crea cuentas durante el intento de inicio de sesión del usuario, mientras que SCIM puede aprovisionar usuarios a través de un proceso automatizado sin conexión, independiente de los intentos de inicio de sesión del usuario.
Esto significa que JIT se enfoca en la incorporación de nuevos usuarios, mientras que SCIM se centra en la gestión completa del ciclo de vida de los usuarios.
Además, JIT es a menudo una extensión de SAML y carece de una implementación estandarizada en todos los sistemas, mientras que SCIM es un protocolo bien definido y estandarizado RFC 7644 para la gestión de identidad. Algunas organizaciones más grandes usan SCIM para el aprovisionamiento de cuentas, integrándolo con sus propios sistemas. Esto puede ser muy complejo y variar caso por caso. Estas organizaciones a menudo tienen un sistema de aprovisionamiento que involucra tanto procesos automatizados como participación manual del admin.
Audiencia (Audience)
La reclamación de audiencia (audience claim) en un token especifica el destinatario previsto, típicamente la aplicación cliente o el recurso API. Garantiza que el token sea utilizado solo por el servicio correcto, mejorando la seguridad al prevenir el acceso no autorizado.
¿Qué es la audiencia (audience)?
En el contexto de Autenticación (Authentication) y Autorización (Authorization) , la audiencia (audience) es un componente clave que define los destinatarios previstos de un token de autorización. Referido como la reclamación aud en JSON Web Token (JWT) , esta reclamación asegura que el token solo sea aceptado por el servicio o aplicación designado. Típicamente, la reclamación de audiencia contiene ya sea el client_id de la aplicación para la cual está destinado el token o una URL que representa el API o recurso al que el token está autorizado a acceder. Al especificar la audiencia, sirve como un control de seguridad para prevenir el uso indebido por servicios o usuarios no autorizados.
¿Cómo funciona la audiencia (audience)?
Cuando un cliente solicita un Token de acceso (Access token) de un authorization server, la reclamación de audiencia se incluye en la respuesta del token. Este valor de audiencia es luego validado por el resource server cuando se presenta el token. El resource server verifica si la reclamación de audiencia en el token coincide con su propio identificador o el identificador del servicio que está protegiendo. Si no coincide, el token será rechazado, mejorando la seguridad en sistemas distribuidos, particularmente en escenarios que involucran múltiples microservicios o APIs. Al controlar la reclamación de audiencia, los desarrolladores pueden asegurar que los tokens se usen en el contexto correcto, añadiendo una capa adicional de protección a los flujos de authentication y authorization de su aplicación.
- Solicitante: La aplicación cliente especifica el valor de audiencia al solicitar un token.
- Emisor: El authorization server incluye la reclamación de audiencia en la respuesta del token.
- Verificador: El destinatario del token verifica la reclamación de audiencia contra su propio identificador. Si la reclamación de audiencia coincide con el identificador del destinatario, el token se considera válido. De lo contrario, se rechaza.
Ejemplo de audiencia en JWT
Reclamación de audiencia en un ID token de OpenID Connect (OIDC)
{
"header": {
"alg": "RS256",
"typ": "JWT",
"kid": "abc123"
},
"payload": {
"iss": "https://auth.logto.io",
"sub": "test_user",
"aud": "client_id_foo",
"exp": 1516239022,
"iat": 1516239022,
"nonce": "n-0S6_WzA2Mj",
"primary_email": "foo@logto.io",
"email_verified": true,
"username": "foo"
},
"signature": "..."
}
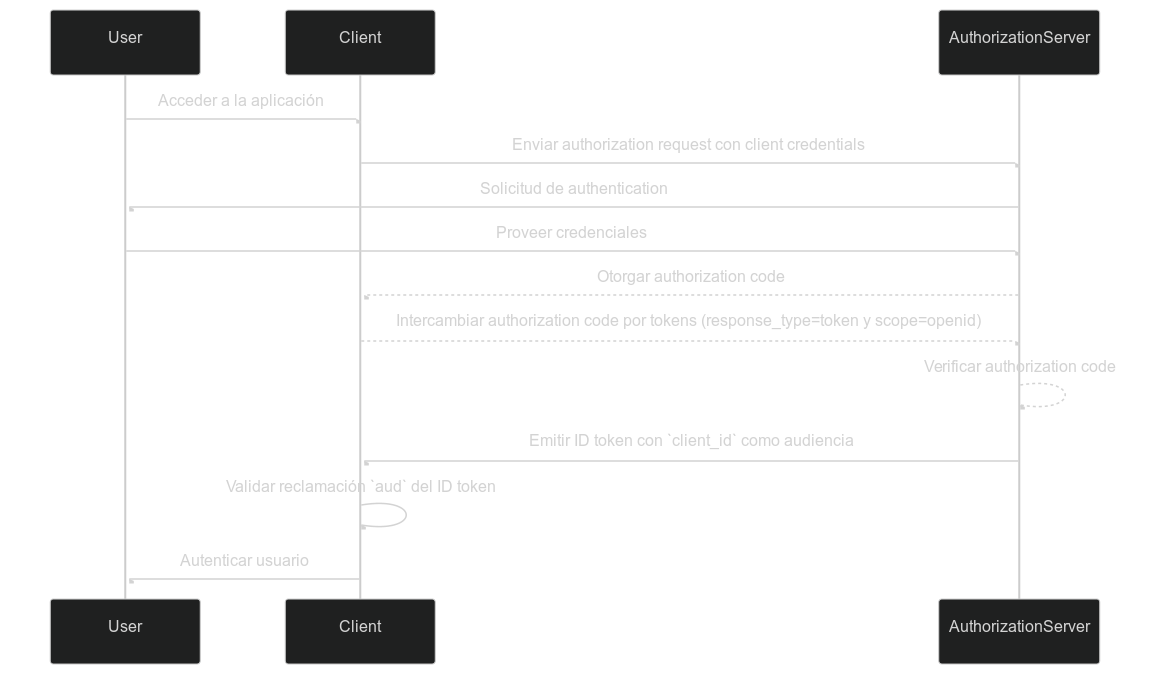
Un Token de ID (ID token) en OpenID Connect (OIDC) es un token de seguridad que contiene información sobre el usuario autenticado, entregado a la aplicación cliente después de una authentication exitosa. A diferencia de los access tokens, que se utilizan para otorgar permiso para acceder a recursos, los ID tokens están diseñados específicamente para transmitir información de identidad del usuario a la parte que confía (cliente). Estos tokens suelen estar codificados como JWTs e incluyen reclamaciones como el identificador del usuario (reclamación sub), el emisor (reclamación iss) y la audiencia (reclamación aud), entre otros.
En este caso, la reclamación aud especifica la audiencia prevista para el ID token, que es la aplicación cliente. El valor de la reclamación aud generalmente corresponde al client_id de la aplicación que solicitó el token. Cuando la aplicación cliente recibe el ID token, puede verificar la reclamación de audiencia para asegurarse de que el token fue emitido para su consumo. Este paso de validación ayuda a prevenir el uso indebido del token y el acceso no autorizado a la información del usuario, mejorando la seguridad del proceso de authentication.
Reclamación de audiencia en un access token
{
"header": {
"alg": "RS256",
"typ": "JWT",
"kid": "abc123"
},
"payload": {
"iss": "https://auth.logto.io",
"sub": "test_user",
"aud": "https://example.logto.app/api/users",
"exp": 1516239022,
"iat": 1516239022,
"scope": "read write",
"client_id": "client_id_foo"
},
"signature": "..."
}
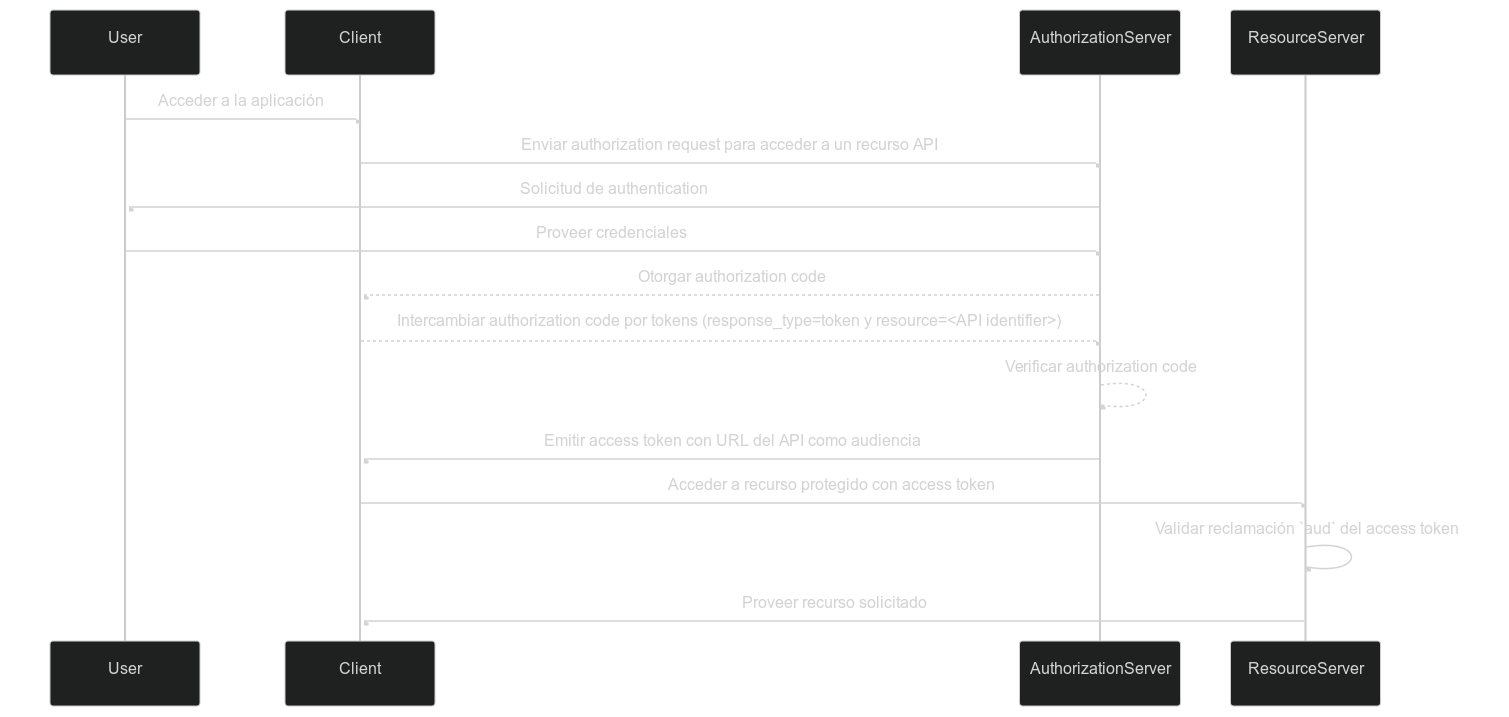
A diferencia del ID token, los Token de acceso (Access token) se utilizan para autorizar el acceso a recursos protegidos, como APIs o servicios. La reclamación aud en un access token especifica el destinatario previsto del token, que típicamente es el API o servicio al que el token está autorizado a acceder. Típicamente, el resource server que aloja el API tiene un dominio diferente de la aplicación cliente que solicitó el token. En este caso, en lugar de un client_id, la reclamación aud contiene la URL del endpoint del API para el cual está destinado el token. Esta URL a menudo se conoce como el resource indicator o API identifier que identifica de manera única el recurso objetivo.
Cuando el resource server recibe un access token, valida la reclamación aud para asegurarse de que el token está destinado para su consumo. Al verificar la audiencia, el resource server puede prevenir el acceso no autorizado a sus recursos y hacer cumplir las políticas de access control basadas en la audiencia prevista del token. Este mecanismo ayuda a proteger datos sensibles y asegura que los access tokens se utilicen en el contexto apropiado, mejorando la seguridad del sistema en general.
Preguntas frecuentes
¿Por qué es importante la reclamación de audiencia en la validación de tokens?
La reclamación de audiencia es crucial en la validación de tokens porque asegura que el token solo sea aceptado por el destinatario previsto. Al verificar la reclamación de audiencia, el destinatario puede prevenir el uso indebido del token y el acceso no autorizado a los recursos. Este control de seguridad es particularmente importante en sistemas distribuidos donde múltiples servicios interactúan entre sí, ya que ayuda a hacer cumplir las políticas de access control y proteger datos sensibles.
¿Puede un token tener múltiples audiencias?
Por razones de seguridad, se recomienda que un token tenga una sola audiencia para prevenir ambigüedades y asegurar que el token se use en el contexto correcto. Sin embargo, algunos escenarios pueden requerir tokens con múltiples audiencias, como cuando un token está destinado a múltiples servicios o APIs dentro del mismo dominio. En tales casos, los desarrolladores deben considerar cuidadosamente las implicaciones de usar tokens de múltiples audiencias e implementar medidas de seguridad apropiadas para mitigar riesgos potenciales.
¿Qué debo usar como mi API identifier en la reclamación de audiencia?
Al especificar la reclamación de audiencia en un access token que representa un API o servicio, se recomienda usar un URI absoluto que identifique de manera única el recurso. Este URI puede ser la URL base del endpoint del API o una ruta de recurso específica a la que el token está autorizado a acceder. Al usar un URI como el API identifier, puedes asegurar que la reclamación de audiencia sea inequívoca y represente con precisión el destinatario previsto del token.
Autenticación (Authentication)
La autenticación (Authentication) es el proceso de verificar la propiedad de la identidad (p. ej., usuario o servicio). Es la base de los sistemas de gestión de identidades y accesos (IAM) y es esencial para asegurar aplicaciones y servicios.
¿Qué es la autenticación (Authentication)?
En resumen: La autenticación (Authentication) responde a la pregunta “¿Qué identidad posees?”
Aquí hay algunos ejemplos típicos de autenticación (Authentication):
- Inicio de sesión con nombre de usuario y contraseña
- Inicio de sesión social (por ejemplo, Iniciar sesión con Google)
- Máquina a máquina (Machine-to-machine) autenticación (Authentication) (por ejemplo, API keys)
No usamos la frase “¿Quién eres?” porque:
- En el ámbito de Gestión de identidades y access (Identity and access management, IAM) , la autenticación (Authentication) se trata de verificar la propiedad de una identidad, no de identificar a la persona o entidad. Por ejemplo, cuando uno de tus familiares utiliza tus credenciales para acceder a tu cuenta, no son tú, pero la identidad para el sistema es la misma.
- La identidad puede ser un usuario, un servicio o un dispositivo. Por ejemplo, un servicio puede autenticarse ante otro servicio utilizando API keys.
Diferencia entre autenticación (Authentication) y autorización (Authorization)
Estos dos términos a menudo se confunden, pero son fundamentalmente diferentes: Autorización (Authorization) responde a la pregunta “¿Qué puedes hacer?”. Además, la autenticación (Authentication) es un requisito previo para la autorización (Authorization) ya que el sistema necesita conocer la identidad antes de decidir qué acciones puede realizar.
Factores de autenticación (Authentication)
La autenticación (Authentication) se puede realizar utilizando uno o más factores. Aquí hay algunos factores comunes:
- Factor de conocimiento: Algo que sabes (por ejemplo, contraseña, PIN)
- Factor de posesión: Algo que tienes (por ejemplo, smartphone, token de seguridad)
- Factor de inherencia: Algo que eres (por ejemplo, huella dactilar, reconocimiento facial)
Autenticación multifactor (Multi-factor authentication, MFA) es una práctica común que combina múltiples factores para aumentar la seguridad. Por ejemplo, cuando inicias sesión en tu cuenta bancaria, es posible que necesites proporcionar una contraseña (factor de conocimiento) y un código único de una aplicación autenticadora (factor de posesión).
Llave de acceso (Passkey) es un factor de autenticación (Authentication) moderno que puede combinar múltiples factores y es resistente a ataques de phishing.
Marcos de autenticación (Authentication) (protocolos)
En lugar de construir un sistema de autenticación (Authentication) propio, se recomienda usar marcos y protocolos establecidos ya que han sido probados en batalla y revisados por expertos en seguridad. Existen diversos marcos y protocolos de autenticación (Authentication) que definen cómo se debe realizar la autenticación (Authentication). Dos comunes son:
- OpenID Connect (OIDC) : Una capa de identidad construida sobre OAuth 2.0 que agrega capacidades de autenticación (Authentication). Es relativamente moderno y ampliamente utilizado para nuevas aplicaciones.
- Lenguaje de marcado para declaraciones de seguridad (Security Assertion Markup Language, SAML) : Un protocolo para el intercambio de datos de autenticación (Authentication) y autorización (Authorization) entre partes. Se utiliza comúnmente en entornos empresariales.
La elección del marco depende de tu caso de uso y requisitos. Para nuevas aplicaciones, se recomienda OIDC debido a su diseño moderno y soporte para JSON Web Token (JWT) .
Sin embargo, trabajar directamente con estos protocolos puede ser complejo y llevar tiempo. Ambos protocolos tienen curvas de aprendizaje pronunciadas y requieren una implementación cuidadosa para garantizar la seguridad. En su lugar, usar un Proveedor de identidad (Identity provider, IdP) que apoye o esté construido sobre estos protocolos puede simplificar en gran medida el proceso de autenticación (Authentication). Un buen proveedor de identidad también proporcionará características adicionales como Autenticación multifactor (Multi-factor authentication, MFA) y Inicio de sesión único (Single Sign-On, SSO) para tus necesidades futuras.
Autenticación multifactor (Multi-factor authentication, MFA)
La autenticación multifactor (MFA) es un mecanismo de seguridad que requiere que los usuarios proporcionen al menos dos formas de identificación para completar el proceso de autenticación. Agrega una capa adicional de seguridad que reduce significativamente el riesgo de acceso no autorizado.
¿Qué es la autenticación multifactor (MFA)?
La autenticación multifactor (MFA) mejora la seguridad al requerir que los usuarios proporcionen múltiples formas de identificación para verificar su identidad. Agrega una capa adicional de seguridad al proceso de Autenticación (Authentication) , lo que hace que sea más difícil para los atacantes obtener acceso no autorizado.
Aquí hay un ejemplo de MFA:

La definición de “factor”
En el ejemplo anterior, hay dos factores:
- Nombre de usuario y contraseña
- Contraseña de un solo uso basada en el tiempo (Time-based one-time password, TOTP) desde una aplicación móvil
Cada factor representa una categoría diferente de credenciales que se pueden usar para autenticar a un usuario (demuestra que eres quien dices ser). En la práctica, los factores pueden categorizarse en tres tipos principales:
| Lo que significa | Factores de verificación | |
|---|---|---|
| Conocimiento | Algo que sabes | Contraseña, Código de verificación por correo electrónico, Código de respaldo |
| Posesión | Algo que tienes | Código de verificación por SMS, OTP de la aplicación de autenticación, OTP de hardware (llave de seguridad), Tarjeta inteligente |
| Inherencia | Algo que eres | Biométricos como huellas dactilares, Face ID |
Una configuración común de MFA involucra la combinación de dos factores de diferentes categorías, como una contraseña (conocimiento) y un Contraseña de un solo uso basada en el tiempo (Time-based one-time password, TOTP) de una aplicación de autenticación (posesión).
¿Por qué es importante MFA?
No existe tal cosa como la seguridad perfecta, solo niveles variables de inseguridad. —Salman Rushdie
La importancia de MFA es evidente en los números: MFA reduce el riesgo de compromiso en un 99.22% en toda la población y en un 98.56% en casos de credenciales filtradas 1 . Con la ayuda de MFA, se pueden tomar acciones más críticas con confianza, como acceder a datos sensibles y realizar transacciones financieras. Es una manera simple pero efectiva de ofrecer un nivel de seguridad mucho más alto que solo una contraseña o autenticación de un solo factor.
MFA en aplicaciones modernas
Como su nombre lo indica, MFA puede involucrar más de dos factores. A medida que aumenta el número de factores, también lo hace el nivel de seguridad y la complejidad del proceso de autenticación, lo cual puede ser menos amigable para el usuario. Mientras que Contraseña de un solo uso basada en el tiempo (Time-based one-time password, TOTP) ha sido una opción popular en los últimos años, nuevas tecnologías como Llave de acceso (Passkey) están surgiendo para proporcionar una experiencia MFA aún más segura y amigable para el usuario.
Por ejemplo, las aplicaciones modernas pueden usar la API WebAuthn para implementar MFA con passkeys, que son credenciales resistentes al phishing aseguradas por criptografía de clave pública. Empresas como Apple han integrado las passkeys con la autenticación biométrica (Touch ID, Face ID) para agregar de manera nativa el factor de inherencia al proceso MFA, aumentando la seguridad y la conveniencia del usuario.
Hagamos una comparación rápida para una mejor comprensión. Suponiendo que tenemos un usuario que tiene:
- Una aplicación de autenticación instalada en su teléfono para generar códigos TOTP.
- Una passkey integrada con la autenticación biométrica de su dispositivo.
Cuando inician sesión en un sitio web con MFA habilitado en su portátil, los dos procesos se verían así:

Es claro que el proceso de WebAuthn requiere menos pasos y mucho menos tiempo para los usuarios. Aún más, empresas como Apple admiten la sincronización de passkeys entre dispositivos (por ejemplo, iPhone, iPad, Mac) para hacer que el proceso de MFA sea más fluido mientras se mantiene un alto nivel de seguridad.
Consideraciones de seguridad
Al implementar MFA, se deben tener en cuenta algunas consideraciones de seguridad:
- Usa una combinación de factores de diferentes categorías para garantizar un mayor nivel de seguridad. Por ejemplo, combinar una contraseña (conocimiento) con un código TOTP (posesión).
- Evita usar SMS como un factor de MFA debido a su susceptibilidad a ataques de intercambio de SIM.
- Las opciones de recuperación no deben eludir MFA. Por ejemplo, si un usuario pierde su aplicación de autenticación, se le debe requerir usar un código de respaldo u otro factor de MFA para recuperar el acceso.
- Impón períodos de enfriamiento entre intentos fallidos de MFA para prevenir ataques de fuerza bruta.
Auth (desambiguación)
El término "auth" a menudo se utiliza como abreviatura de authentication (autenticación) o authorization (autorización). Estos conceptos están relacionados pero son fundamentalmente diferentes.
Auth
Esta página es una desambiguación para el término “auth”. A menudo se utiliza como una abreviatura para:
- Autenticación (Authentication): El proceso de verificar la propiedad de la identidad (por ejemplo, usuario o servicio). Responde a la pregunta “¿Qué identidad posees?”
- Autorización (Authorization): El proceso de determinar qué acciones puede realizar una identidad sobre un recurso. Responde a la pregunta “¿Qué puedes hacer?”
[!Note] A veces, authentication (autenticación) y authorization (autorización) se refieren como “AuthN” y “AuthZ”, respectivamente.
Estos dos conceptos son esenciales en el ámbito de Gestión de identidades y access (Identity and access management, IAM) , pero son fundamentalmente diferentes. Veamos un ejemplo: Una aplicación web MyStorage tiene la capacidad de subir archivos y conectarse a Google Drive. Un flujo de usuario típico sería:

En este flujo, el usuario realiza dos pasos de authentication (autenticación): uno con MyStorage (paso 1) y otro con Google (paso 6); y un paso de authorization (autorización): otorgar acceso a Google Drive (paso 8).
¿A cuál te refieres?
Cuando ves el término “auth”, es importante aclarar si se refiere a authentication (autenticación) o authorization (autorización); de lo contrario, podrías esperar que ambos procesos estén cubiertos (tal como lo hace este sitio web).
Autorización (Authorization)
La autorización es el proceso de determinar qué acciones puede realizar una identidad en un recurso. Es un mecanismo de seguridad fundamental para definir y hacer cumplir políticas de acceso.
¿Qué es la autorización (Authorization)?
TL;DR: La autorización (Authorization) responde a la pregunta “¿Qué puedes hacer?”
La autorización (Authorization) es un proceso de toma de decisiones que determina si una identidad (usuario, servicio o dispositivo) tiene los permisos necesarios para realizar una acción específica en un recurso. Veamos algunos ejemplos:
- En un editor de documentos en línea, un usuario puede compartir un documento con otros.
- En un servicio de almacenamiento en la nube, un servicio puede leer y escribir archivos en una carpeta específica.
- En un sistema de hogar inteligente, un dispositivo puede encender las luces en la sala de estar.
Todos estos ejemplos implican una identidad (sujeto) realizando una acción en un recurso. Por supuesto, la autorización (Authorization) también puede fallar, como cuando un usuario intenta eliminar un archivo al que no tiene permiso para acceder.
El modelo básico para la autorización (Authorization) es simple: Si identidad realiza acción en recurso, entonces aceptar o denegar.
Diferencia entre autenticación (Authentication) y autorización (Authorization)
La autenticación (authentication) y la autorización (Authorization) a menudo se confunden, pero son fundamentalmente diferentes: Autenticación (Authentication) responde a la pregunta “¿Qué identidad posees?”. Además, en la mayoría de los casos, la autorización (Authorization) ocurre después de la autenticación (authentication) porque el sistema necesita conocer la identidad antes de tomar decisiones de acceso.
Diferencia entre autorización (Authorization) y control de acceso (Access control)
La autorización (Authorization) es un subconjunto del control de acceso (Access control). El control de acceso es el concepto más amplio que incluye la autorización (Authorization) y otras restricciones en la gestión de acceso. En otras palabras, el control de acceso (Access control) es un término general que describe la restricción selectiva del acceso a los recursos, mientras que la autorización (Authorization) se refiere específicamente al proceso de toma de decisiones.
¿Cómo funciona la autorización (Authorization)?
La autorización (Authorization) normalmente se implementa utilizando Modelos de control de acceso (Access control) . Estos definen cómo se asignan y aplican los permisos en un sistema.
Marcos de trabajo (protocolos) de autorización (Authorization)
Mientras que OAuth 2.0 es un marco muy popular para la autorización (Authorization), vale la pena mencionar que OAuth 2.0 no define qué modelo de control de acceso (Access control) usar. En su lugar, se enfoca en la delegación de la autorización (Authorization) y la emisión de tokens de acceso (access tokens).
Dicho esto, OAuth 2.0 es adecuado para escenarios de autorización de terceros donde un usuario otorga permiso a un cliente para acceder a sus recursos. Por ejemplo, cuando inicias sesión en un sitio web usando tu cuenta de Google, estás autorizando al sitio web para que acceda a tu perfil de Google.
Si estás tratando con autorización de primera parte (por ejemplo, dentro de tu aplicación u organización), es posible que necesites implementar un modelo de control de acceso (Access control) como Control de acceso basado en roles (Role-based access control, RBAC) o Control de acceso basado en atributos (Attribute-based access control, ABAC) . La combinación de OpenID Connect (OIDC) y modelos de control de acceso (Access control) puede proporcionar una base sólida tanto para la autenticación (authentication) como para la autorización (Authorization).
En lugar de construir un sistema de autorización (Authorization) propio, se recomienda utilizar un Proveedor de identidad (Identity provider, IdP) que ofrezca capacidades de autenticación (authentication) y autorización (Authorization). Un buen proveedor de identidad (identity provider) manejará la complejidad del control de acceso (Access control) y proporcionará una solución segura y escalable para tus aplicaciones.
Cifrado Web JSON (JSON Web Encryption, JWE)
JSON Web Encryption (JWE) es una forma estándar de cifrar y descifrar datos en formato JSON. Se utiliza a menudo para proteger información sensible en los Tokens Web JSON (JWTs) en tránsito.
¿Qué es JSON Web Encryption (JWE)?
Como se define en el RFC 7516, JSON Web Encryption (JWE) es un mecanismo para cifrar y descifrar datos en formato JSON. Agrega una capa de confidencialidad a los datos, y es particularmente útil al transmitir información sensible a través de una red no confiable.
JWE se utiliza a menudo junto con Tokens Web JSON (JWTs) para proteger los datos de carga útil. Por ejemplo, un Token de ID (ID token) o un Token de acceso (Access token) pueden cifrarse utilizando JWE para asegurar que los datos estén protegidos durante la transmisión.
¿Cómo funciona JWE?
JWE tiene dos formatos de serialización: compacto y JSON. Cada formato tiene su propia manera de representar los datos cifrados.
Serialización compacta
En la serialización compacta, el JWE se representa como una cadena con cinco partes codificadas en Base64URL separadas por puntos (.). Las cinco partes son:
{{header}}.{{encrypted-key}}.{{iv}}.{{ciphertext}}.{{tag}}
Cada parte tiene un propósito específico:
header: Contiene metadatos sobre el algoritmo de cifrado y la gestión de claves.encrypted-key: La clave de cifrado de contenido encriptada (CEK) utilizada para cifrar la carga útil.iv: El vector de inicialización utilizado en el proceso de cifrado.ciphertext: Los datos de carga útil cifrados.tag: La etiqueta de autenticación utilizada para verificar la integridad de los datos cifrados.
Serialización JSON
La serialización JSON es más extensa y proporciona una forma estructurada de representar el JWE. El JWE se representa como un objeto JSON con las siguientes propiedades:
{
"protected": "{{protected-header}}",
"unprotected": "{{unprotected-header}}",
"header": "{{header}}",
"encrypted_key": "{{encrypted-key}}",
"iv": "{{iv}}",
"ciphertext": "{{ciphertext}}",
"tag": "{{tag}}",
"aad": "{{additional-authenticated-data}}"
}
protected: Contiene la cabecera protegida codificada en Base64URL.unprotected: Contiene la cabecera desprotegida compartida de JWE.header: Contiene la cabecera desprotegida por destinatario de JWE.encrypted_key: Contiene la clave de cifrado de contenido encriptada (CEK) codificada en Base64URL.iv: Contiene el vector de inicialización codificado en Base64URL.ciphertext: Contiene el texto cifrado codificado en Base64URL (carga útil cifrada).tag: Contiene la etiqueta de autenticación codificada en Base64URL.aad: Contiene los datos adicionales autenticados codificados en Base64URL.
El cliente debería poder descifrar el JWE utilizando la clave y el algoritmo apropiados. Se puede utilizar una clave precomunicada o una clave derivada de un protocolo de acuerdo de claves para descifrar el JWE.
Por ejemplo, un Token de ID (ID token) puede cifrarse utilizando JWE, y el cliente puede descifrarlo utilizando la clave apropiada obtenida del endpoint jwks_uri del proveedor de OpenID.
Clave de API (API key)
Una clave de API es un identificador único utilizado para autenticar y autorizar un cliente al acceder a una API. Sirve como un token secreto incluido en las solicitudes de API para verificar la identidad del cliente y permitir el acceso a recursos o servicios específicos. Las claves de API se utilizan típicamente en comunicaciones de servidor a servidor o al acceder a datos públicos.
¿Qué es una clave de API?
Las claves de API se utilizan para identificar y autorizar la aplicación o servicio que realiza la llamada. Generalmente tienen una larga duración y son estáticas hasta que se rotan y a menudo tienen un conjunto fijo de permisos. Se utilizan principalmente para comunicaciones de servidor a servidor o para acceder a datos públicos, estos tokens generalmente no representan a un usuario específico.
¿Cómo funciona una clave de API?
Una clave de API es una larga cadena de caracteres generada por el proveedor de la API y compartida con usuarios autorizados. Esta clave debe incluirse en el encabezado de la solicitud al acceder a la API. Las claves de API son simples y efectivas para necesidades básicas de seguridad. Por ejemplo, servicios populares como Google Maps API y AWS proporcionan claves de API para controlar el acceso y monitorear el uso.
curl -GET https://api.example.com/endpoint -H "Authorization: api-key TU_API_KEY"
Las claves de API no son tan efectivas como otras formas de autenticación de API, como OAuth 2.0 y JSON Web Token (JWT) , pero aún juegan un papel importante al ayudar a los productores de API a monitorear el uso, ya que es el método más sencillo y ampliamente utilizado para asegurar las APIs.
¿Cuáles son sus pros y contras?
Pros
- Simple de implementar: Las claves de API son fáciles de implementar y usar. Implican adjuntar una clave al encabezado de la solicitud, lo que lo convierte en un método sencillo para que los desarrolladores y clientes lo entiendan y utilicen.
- Fácil de monitorear: Las claves de API son fáciles de monitorear. Puedes rastrear el uso de cada clave y revocarlas si es necesario.
- Limitación de tasa efectiva: Las claves de API son efectivas para la limitación de tasa. Puedes establecer un límite en el número de solicitudes por clave para prevenir abusos.
- Adecuado para datos no sensibles: Las claves de API son adecuadas para datos no sensibles o APIs disponibles públicamente, donde los requisitos de seguridad son menores.
Contras
- Seguridad limitada: Las claves de API no son lo suficientemente seguras para datos sensibles, especialmente para aplicaciones del lado del cliente. A menudo se utilizan en comunicaciones de máquina a máquina.
- No adecuado para la autenticación de usuarios: Las claves de API están vinculadas a aplicaciones o sistemas, no a usuarios individuales, lo que dificulta identificar usuarios específicos o rastrear sus acciones.
- Sin expiración de token: Las claves de API son típicamente estáticas y no expiran. Si una clave se compromete, podría ser mal utilizada indefinidamente a menos que se regenere manualmente.
¿Cuáles son los casos de uso para las claves de API?
- Comunicación de servicio a servicio: Las claves de API son adecuadas para escenarios donde las aplicaciones necesitan comunicarse con APIs directamente a través de CLIs. Por ejemplo, llamar a las APIs de OpenAI.
- APIs públicas: Al exponer APIs al público, las claves de API proporcionan un método sencillo de control de acceso.
- Configuración simplificada: Para necesidades de autenticación rápidas y simples, especialmente en la fase de desarrollo. A diferencia de la autenticación de máquina a máquina, las claves de API no requieren registro de cliente previo, y tampoco necesitan intercambiarse por un access token. Simplemente pasas tu clave de API como un parámetro en tu solicitud y simplemente funciona.
¿Cuál es la diferencia entre los Tokens de Acceso Personal (PAT) y la comunicación de Máquina a Máquina (M2M)?
Al hablar de claves de API, los tokens de acceso personal y Máquina a máquina (Machine-to-machine) también pueden mencionarse juntos ya que todos pueden acceder programáticamente a recursos de API a través de comandos CLI, o establecer comunicación entre servicios de backend.
Tokens de Acceso Personal (PATs)
Un token de acceso personal también es una cadena pero representa la identidad y permisos de un usuario específico, se genera dinámicamente tras una autenticación o inicio de sesión exitoso, y típicamente tiene una duración limitada pero puede ser renovado. Proporciona un control de acceso detallado a datos y capacidades específicas del usuario y se utilizan comúnmente para herramientas CLI, scripts o acceso personal a API. La principal diferencia es que es más específico y se utiliza para acciones específicas del usuario.
Máquina a Máquina (M2M)
La comunicación M2M es cuando los dispositivos intercambian datos automáticamente sin intervención humana en un sentido más amplio.
En el contexto de OpenID Connect (OIDC) (u OAuth 2.0 ), las aplicaciones M2M usan el Flujo de credenciales del cliente (Client credentials flow) , como se define en el protocolo OAuth 2.0 RFC 6749 , que soporta protocolos estándar similares. Generalmente involucra a una aplicación cliente (una máquina o servicio) accediendo a recursos ya sea por sí misma o en nombre de un usuario. Es ideal para situaciones donde solo los clientes de confianza pueden acceder a servicios de backend.
Clave de firma (Signing key)
Una clave de firma es una clave criptográfica utilizada para firmar y verificar JSON Web Tokens en OpenID Connect (OIDC). Se utiliza para garantizar la integridad y autenticidad de los tokens emitidos por el proveedor OpenID.
¿Qué es una clave de firma?
En el contexto de OpenID Connect (OIDC) , una clave de firma (signing key), generalmente un par de claves asimétricas, se utiliza para firmar y verificar JSON Web Tokens (JWTs) . Los proveedores OpenID utilizan claves de firma para firmar tokens como ID tokens y access tokens para garantizar su integridad y autenticidad.
Aunque el concepto de claves de firma puede ser más amplio, nos centraremos en cómo se utilizan en OIDC para asegurar tokens. Otros casos de uso, como firmar correos electrónicos, documentos y paquetes de software, pueden derivarse de los mismos principios.
Ejemplo: Firmado de ID token
Cuando un usuario se autentica (authentication) con un proveedor OpenID, el proveedor emite un ID token que contiene información del usuario ( claims ) y es firmado por la clave de firma del proveedor. Dado que el ID token es un JWT, consta de tres partes: encabezado, carga útil y firma.
1. Encabezado
Supongamos que el encabezado es:
{
"alg": "ES384",
"typ": "JWT"
}
El JSON indica que el ID token está firmado utilizando el algoritmo ECDSA con la curva P-384. El campo typespecifica que el tipo de token es JWT.
2. Carga útil
La carga útil contiene información básica del usuario:
{
"sub": "1234567890",
"name": "Alice"
}
El sub claim es el identificador único del usuario, y name es su nombre para mostrar.
3. Firmar el token
De acuerdo con el formato JWT, el encabezado y la carga útil deben estar codificados en Base64URL y concatenados con un . para firmar:
{{header}}.{{payload}}
En este caso, el valor sería:
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkFsaWNlIn0
Supongamos que el proveedor OpenID utiliza la siguiente clave privada para firmar el token:
-----BEGIN PRIVATE KEY-----
MIG2AgEAMBAGByqGSM49AgEGBSuBBAAiBIGeMIGbAgEBBDBW9PDXInlNT2hjOtQr
g4pkVkyJsKia33dHrsbOG4Z77pfYN7SYZCHh9YdLXTTKinehZANiAAQX/FB1s6Gj
YnDSGCY08PRUAQ8CCRCt8Ph/VDHfLj1xSbrjp8wFf0NjH7jcfNebpV1fvu4XKbP3
Ro7h0G6elN1TMsVECJPv4ieDNkYOsgT4UboJypC5E/rmvrlJTMM6Y/k=
-----END PRIVATE KEY-----
Para firmar el token, el proveedor OpenID necesita usar la clave privada para generar una firma mediante:
signature = sign(header + '.' + payload, private_key)
Luego, la firma codificada en Base64URL es:
Cjy6A_FHnwQBP0hRawoGTkRy8m8o0Ncc1q4BeyxYr0fxhKYmJJinIWZPXJdaAXRO9wOFuH2-UML2yWHjot_LnCPO6362asMvgNkEJMZ6UtqyOPlsCOJ7voTPOCT6sYu2
4. Ensamblar el JWT
Finalmente, el proveedor OpenID ensambla el JWT concatenando el encabezado, la carga útil y la firma con .:
{{header}}.{{payload}}.{{signature}}
En este caso, el ID token sería:
eyJhbGciOiJFUzM4NCIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkFsaWNlIn0.Cjy6A_FHnwQBP0hRawoGTkRy8m8o0Ncc1q4BeyxYr0fxhKYmJJinIWZPXJdaAXRO9wOFuH2-UML2yWHjot_LnCPO6362asMvgNkEJMZ6UtqyOPlsCOJ7voTPOCT6sYu2
El ID token está ahora listo para ser enviado al Cliente (Client) para su procesamiento posterior.
5. Verificar el token
Cuando el cliente recibe el ID token, puede verificar la firma utilizando la clave pública del proveedor OpenID. Por lo general, la clave pública está disponible a través del endpoint de Descubrimiento de OpenID Connect (OpenID Connect Discovery) (jwks_uri) en el formato de un Conjunto de Claves Web JSON (JWKS) .
Para este ejemplo, la clave pública es:
-----BEGIN PUBLIC KEY-----
MHYwEAYHKoZIzj0CAQYFK4EEACIDYgAEF/xQdbOho2Jw0hgmNPD0VAEPAgkQrfD4
f1Qx3y49cUm646fMBX9DYx-43HzXm6VdX77uFymz90aO4dBunpTdUzLFRAiT7+In
gzZGDrIE+FG6CcqQuRP65r65SUzDOmP5
-----END PUBLIC KEY-----
Y el valor JWK correspondiente es:
{
"kty": "EC",
"crv": "P-384",
"x": "F_xQdbOho2Jw0hgmNPD0VAEPAgkQrfD4f1Qx3y49cUm646fMBX9DYx-43HzXm6Vd",
"y": "X77uFymz90aO4dBunpTdUzLFRAiT7-IngzZGDrIE-FG6CcqQuRP65r65SUzDOmP5"
}
Ahora, el cliente puede verificar la firma utilizando la clave pública.
Elegir el algoritmo correcto
Existen varios algoritmos disponibles para firmar JWTs:
- Algoritmos simétricos: HMAC con la familia SHA (por ejemplo, HS256, HS384, HS512) es un algoritmo simétrico que utiliza la misma clave tanto para firmar como para verificar. No se recomienda en la mayoría de los casos ya que la clave secreta necesita ser compartida entre las partes.
- Algoritmos asimétricos: RSA (por ejemplo, RS256, RS384, RS512) y ECDSA (por ejemplo, ES256, ES384, ES512) son algoritmos asimétricos que utilizan un par de claves: una clave privada para firmar y una clave pública para verificar.
- RSA es ampliamente utilizado y compatible con muchas bibliotecas y plataformas. Sin embargo, tiene un tamaño de clave y de firma mucho mayor en comparación con ECDSA.
- ECDSA es más eficiente y genera firmas más pequeñas, lo que lo convierte en una mejor opción para entornos restringidos. Dado que es menos común, asegúrate de que tu plataforma lo soporte.
ECDSA debería ser la opción preferida para nuevas aplicaciones debido a sus beneficios en rendimiento y seguridad.
Otros escenarios de clave de firma
Aunque el ejemplo anterior se centra en ID tokens en OIDC, el concepto de clave de firma se utiliza ampliamente en varios escenarios, como firmar correos electrónicos, documentos y paquetes de software. Los principios clave permanecen iguales:
- Para claves simétricas, se utiliza la misma clave tanto para firmar como para verificar. Esto es adecuado para escenarios donde las partes pueden compartir la clave de manera segura, o hay una sola entidad responsable de firmar y verificar.
- Para claves asimétricas, se utiliza una clave privada para firmar y una clave pública correspondiente para verificar. Esto es adecuado para la mayoría de los escenarios donde las partes que firman y verifican son entidades diferentes.
Clave Web JSON (JSON Web Key, JWK)
Una Clave Web JSON (JWK) es un formato basado en JSON utilizado para representar claves criptográficas. Cuando múltiples JWK deben agruparse, se organizan en un Conjunto de Claves Web JSON (JWKS).
¿Qué es una Clave Web JSON (JWK)?
Una Clave Web JSON (JWK) es un formato basado en JSON utilizado para representar claves criptográficas. Se utiliza ampliamente en el contexto de JSON Web Signature (JWS) y Cifrado Web JSON (JSON Web Encryption, JWE) para validar la integridad y confidencialidad de JSON Web Tokens (JWT) . También se usa en OpenID Connect (OIDC) para la gestión de identidad y acceso (access management).
Por ejemplo, una clave pública ECDSA codificada en PEM:
-----BEGIN PUBLIC KEY-----
MHYwEAYHKoZIzj0CAQYFK4EEACIDYgAEF/xQdbOho2Jw0hgmNPD0VAEPAgkQrfD4
f1Qx3y49cUm646fMBX9DYx+43HzXm6VdX77uFymz90aO4dBunpTdUzLFRAiT7+In
gzZGDrIE+FG6CcqQuRP65r65SUzDOmP5
-----END PUBLIC KEY-----
…puede representarse como un JWK:
{
"kty": "EC",
"crv": "P-384",
"x": "F_xQdbOho2Jw0hgmNPD0VAEPAgkQrfD4f1Qx3y49cUm646fMBX9DYx-43HzXm6Vd",
"y": "X77uFymz90aO4dBunpTdUzLFRAiT7-IngzZGDrIE-FG6CcqQuRP65r65SUzDOmP5"
}
¿Cómo funciona un JWK?
Dado que el JWK es un formato basado en JSON, puede contener metadatos ricos sobre la clave en comparación con formatos tradicionales como PEM. Aquí hay algunos atributos comunes en un JWK:
kty(Key Type): La familia de algoritmos criptográficos utilizada con la clave. Los valores comunes incluyenRSA,ECyoct.ECha sido marcado como “Recomendado+” en RFC 7518 .use(Public Key Use): El uso previsto de la clave pública. Los valores comunes incluyensig(firma) yenc(encriptación).key_ops(Key Operations): Las operaciones de clave admitidas por la clave. Los valores comunes incluyensign,verify,encryptydecrypt.alg(Algorithm): El algoritmo previsto para su uso con la clave. Dependiendo del tipo de clave, el algoritmo puede variar. Por ejemplo, se puede usarRS256con una clave RSA, mientras queES256se puede usar con una clave EC.kid(Key ID): Un identificador único para la clave. Puede usarse para identificar una clave específica en un conjunto de claves.
Excepto kty, todos los demás atributos son opcionales y pueden usarse para proporcionar contexto adicional sobre la clave. Según el valor de kty, otros atributos pueden ser necesarios u opcionales. En el ejemplo anterior, el JWK representa una clave ECDSA (kty: "EC") con una curva P-384 (crv: "P-384"). Los atributos x e ycontienen las coordenadas de la clave pública.
Aquí hay otro ejemplo no normativo de un JWK de clave pública RSA:
{
"kty": "RSA",
"use": "sig",
"alg": "RS256",
"n": "0vx7agoebGcQSuuPiLJXZpt...-TmV4HCA1T8jXg3fE2VbA",
"e": "AQAB",
"kid": "2011-04-29-1234"
}
Para obtener información detallada sobre los atributos de JWK y sus significados, consulte RFC 7517 .
Conjunto de Claves Web JSON (JWKS)
Cuando múltiples JWK deben agruparse, se organizan en un Conjunto de Claves Web JSON (JWKS). Un JWKS es un objeto JSON que contiene un array de JWK. Es comúnmente utilizado en la respuesta del endpoint jwks_uri en Descubrimiento de OpenID Connect (OpenID Connect Discovery) para proporcionar las claves públicas para la validación de signing-key de JWT.
Aquí hay un ejemplo no normativo de un JWKS que contiene dos JWK:
{
"keys": [
{
"kty": "RSA",
"use": "sig",
"alg": "RS256",
"n": "0vx7agoebGcQSuuPiLJXZpt...-TmV4HCA1T8jXg3fE2VbA",
"e": "AQAB",
"kid": "2011-04-29-1234"
},
{
"kty": "EC",
"crv": "P-384",
"x": "F_xQdbOho2Jw0hgmNPD0VAEPAgkQrfD4f1Qx3y49cUm646fMBX9DYx-43HzXm6Vd",
"y": "X77uFymz90aO4dBunpTdUzLFRAiT7-IngzZGDrIE-FG6CcqQuRP65r65SUzDOmP5"
}
]
}
En este ejemplo, el JWKS contiene dos JWK: una clave RSA y una clave EC. El atributo keys es un array de JWK, cada uno representando una clave diferente.
Cliente (Client)
En OAuth 2.0 y OpenID Connect (OIDC), un cliente es una aplicación que solicita autenticación (authentication) o autorización (authorization) en nombre de un usuario o de sí misma. Los clientes pueden ser públicos o confidenciales (privados), y utilizan diferentes tipos de concesiones para obtener tokens.
¿Qué es un cliente?
Un cliente, en el contexto de OAuth 2.0 y OpenID Connect (OIDC) , es una aplicación que solicita autenticación (authentication) o autorización (authorization). Por ejemplo, cuando un usuario hace clic en “Iniciar sesión con Google” en una aplicación, la aplicación actúa como un cliente que solicita autorización a Google.
“Cliente” y “aplicación” a menudo se usan indistintamente en el contexto de Gestión de identidades y access (Identity and access management, IAM) .
Existen múltiples categorizaciones de clientes basadas en sus capacidades y niveles de confianza, pero para los frameworks, una distinción significativa es entre clientes públicos y confidenciales. Esto afecta cómo el cliente puede obtener tokens y los tipos de concesiones que puede usar.
Clientes públicos
Los clientes públicos son aplicaciones que no pueden mantener sus credenciales confidenciales, lo que significa que el propietario del recurso (usuario) puede acceder a ellas. Ejemplos de clientes públicos incluyen:
- Aplicaciones de una sola página (SPAs)
- Aplicaciones móviles
- Aplicaciones de escritorio
Podrías argumentar que las aplicaciones móviles y de escritorio tienen capacidades de almacenamiento seguro, pero la mayoría de los frameworks las consideran clientes públicos porque se distribuyen a los usuarios finales y se asume que los usuarios finales pueden acceder a las credenciales.
Clientes confidenciales
Los clientes confidenciales (privados) son aplicaciones que pueden almacenar información sensible de manera confidencial sin exponerla a los propietarios de los recursos (usuarios finales). Ejemplos de clientes confidenciales incluyen:
- Servidores web
- Servicios backend
¿Cómo funciona un cliente?
Autenticación (authentication) y autorización (authorization) del usuario
Cuando un cliente quiere autenticar a un usuario, un cliente inicia una Solicitud de autorización (Authorization request) al Servidor de autorización (Authorization server) para obtener un Token de acceso (Access token) . El cliente debe incluir los parámetros necesarios en la solicitud, como el ID del cliente, la URI de redirección y los ámbitos (scopes). Aquí tienes un diagrama de secuencia simplificado del flujo de código de autorización (authorization code flow):

En este ejemplo, Google actúa como el authorization server que emite un access token al cliente (MyApp) después de que el usuario inicia sesión exitosamente. El cliente puede entonces usar el access token para obtener el perfil del usuario (recurso protegido) en Google.
Para los clientes de OpenID Connect (OIDC), el cliente necesita iniciar una Solicitud de autenticación (Authentication request) para autenticar al usuario. Utiliza el mismo endpoint que el authorization request, pero los parámetros y la respuesta son diferentes.
Comunicación máquina a máquina
Para la comunicación Máquina a máquina (Machine-to-machine) , el cliente puede usar el Flujo de credenciales del cliente (Client credentials flow) para enviar directamente una Solicitud de token (Token request) al authorization server. El cliente debe incluir el ID del cliente, el secreto del cliente y los ámbitos (scopes) en la solicitud.
Consideraciones de seguridad
Tipos de clientes
El tipo de cliente (público o privado) afecta las consideraciones de seguridad para el cliente.
- Los clientes públicos no deben usar el client credentials flow porque no pueden almacenar de forma segura el secreto del cliente. En su lugar, se recomienda el uso del Flujo de código de autorización (Authorization code flow) con Prueba de clave para el intercambio de códigos (Proof Key for Code Exchange, PKCE) para que los clientes públicos autentiquen a los usuarios.
- Los clientes confidenciales pueden usar el client credentials flow para la comunicación máquina a máquina. Deben almacenar de forma segura el secreto del cliente y usarlo solo en entornos seguros.
Almacenamiento de tokens
Los clientes deben usar el nivel más alto de seguridad posible para almacenar tokens. Por ejemplo, en aplicaciones web, se recomiendan cookies HTTP-only para almacenar access tokens y prevenir ataques XSS.
Expiración de tokens
Los access tokens tienen una vida útil limitada para reducir el riesgo de acceso no autorizado. Los clientes deben manejar la expiración de los tokens de manera eficiente usando refresh tokens para obtener nuevos access tokens.
Revocación de tokens
Los clientes deben estar preparados para manejar la revocación de tokens. Si el usuario cierra sesión o el authorization server revoca el token, el cliente debe borrar el token del almacenamiento del lado del cliente.
Concesión de OAuth 2.0 (OAuth 2.0 grant)
Una concesión de autorización de OAuth 2.0 (OAuth 2.0 grant, a veces referida como "tipo de concesión de OAuth 2.0" o "flujo de OAuth 2.0"), es un método utilizado por los clientes para obtener un access token (token de acceso) de un authorization server (servidor de autorización). Es una parte esencial para que los clientes de OAuth autentiquen y autoricen identidades.
¿Qué es una concesión de OAuth 2.0 (OAuth 2.0 grant)?
Una concesión de OAuth 2.0 (OAuth 2.0 grant) es un proceso de autorización que permite a un Cliente (Client) solicitar un Token de acceso (Access token) de un Servidor de autorización (Authorization server). También puede escuchar otros términos relacionados con este concepto, así que aclaremos antes de profundizar:
- Concesión de OAuth 2.0 (OAuth 2.0 grant): También conocida como “tipo de concesión de OAuth 2.0”, “flujo de OAuth 2.0” o “concesión de autorización de OAuth 2.0”. En la mayoría de los contextos, estos términos se refieren al mismo concepto.
- Servidor de autorización (Authorization server): El servidor que emite access tokens (tokens de acceso) al cliente. En OpenID Connect (OIDC), el servidor de autorización es el mismo que el Proveedor de OpenID (OP).
- Solicitud de autorización (Authorization request): La solicitud realizada por el cliente al servidor de autorización para obtener un access token (token de acceso). En OpenID Connect (OIDC), también se refiere a una Solicitud de autenticación (Authentication request) .
Para mayor claridad, usaremos los términos iniciales mencionados anteriormente de manera consistente a lo largo de este artículo.
El proceso general de una concesión de OAuth 2.0 (OAuth 2.0 grant) es bastante simple:
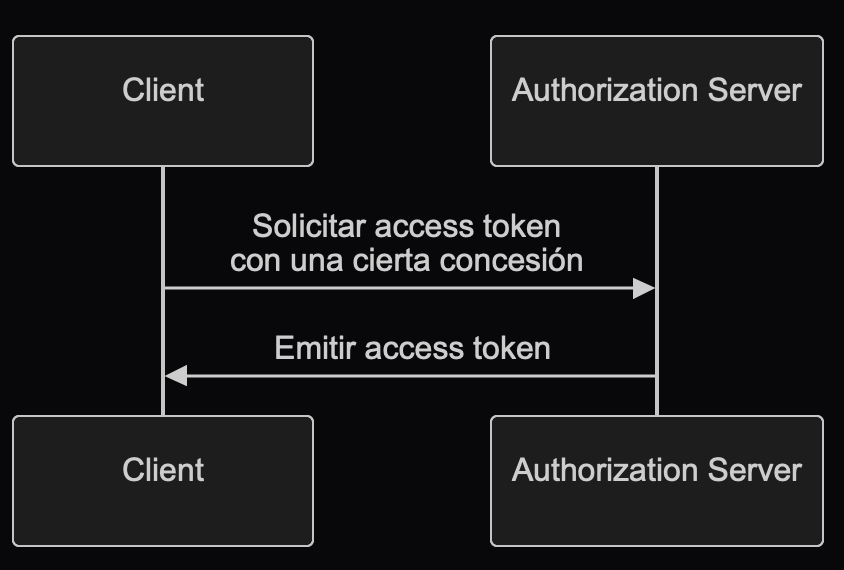
Después de que el cliente recibe el access token (token de acceso), puede usarlo para acceder a recursos protegidos (por ejemplo, APIs) en nombre de un usuario o de sí mismo.
Tenga en cuenta que según la concesión específica, el cliente y el servidor de autorización pueden intercambiar información adicional e involucrar más pasos en el proceso. Por ejemplo, la concesión de código de autorización implica la autenticación y autorización del usuario, la generación de código y el intercambio de tokens.
Diferentes concesiones de OAuth 2.0 (OAuth 2.0 grants)
La especificación básica de OAuth 2.0 define cuatro concesiones que los clientes pueden usar para obtener access tokens (tokens de acceso):
- Concesión de código de autorización: La concesión más segura y recomendada para la mayoría de las aplicaciones. Está obligado a usar Prueba de clave para el intercambio de códigos (Proof Key for Code Exchange, PKCE) para todos los clientes en OAuth 2.1.
- Concesión implícita: Una concesión simplificada que está en desuso en OAuth 2.1 debido a preocupaciones de seguridad.
- Concesión de credenciales de contraseña del propietario del recurso (ROPC): Una concesión donde las credenciales del usuario se intercambian directamente por un access token (token de acceso). No se recomienda para la mayoría de las aplicaciones debido a riesgos de seguridad.
- Concesión de credenciales de cliente: Una concesión utilizada por Clientes confidenciales para obtener un access token (token de acceso) sin la participación del usuario.
A medida que la industria evoluciona, las concesiones implícitas y ROPC están siendo descontinuadas en favor de flujos más seguros y estandarizados. Para nuevas aplicaciones, las opciones son claras:
- Para la autenticación y autorización de usuarios, use la concesión de código de autorización con PKCE.
- Para la comunicación Máquina a máquina (Machine-to-machine), use la concesión de credenciales de cliente.
Otras concesiones de OAuth 2.0 (OAuth 2.0 grants)
Además de las cuatro concesiones básicas, existen otras extensiones que definen nuevas concesiones para casos de uso específicos. Por ejemplo:
- La concesión de autorización de dispositivo es una concesión diseñada para dispositivos con capacidades de entrada limitadas, como televisores inteligentes y dispositivos IoT.
- El flujo híbrido es una concesión de OpenID Connect que combina la concesión de código de autorización con la concesión implícita.
Concesiones en OpenID Connect (OIDC)
En OpenID Connect (OIDC) , el concepto de concesiones se amplía para incluir ID tokens que representan información de identidad del usuario además de los access tokens (tokens de acceso). OIDC extiende dos concesiones de OAuth 2.0 (código de autorización e implícito) para incluir ID tokens, e introduce una nueva concesión llamada flujo híbrido que combina ambos.
Al igual que OAuth 2.0, solo se recomienda usar la concesión de código de autorización con PKCE en OIDC para la autenticación y autorización de usuarios.
Mientras tanto, dado que OIDC está construido sobre OAuth 2.0, otras concesiones como la concesión de credenciales de cliente aún pueden utilizarse en el mismo servidor de autorización, siempre que el servidor las admita.
Contraseña de un solo uso (One-time password, OTP)
Una contraseña de un solo uso (OTP) es un código único y temporal que se utiliza para una sola transacción o sesión de inicio de sesión.
¿Qué es OTP?
Una contraseña de un solo uso (OTP) es un código único y temporal que se utiliza para una sola transacción o sesión de inicio de sesión. A diferencia de las contraseñas tradicionales, que son estáticas y permanecen iguales hasta que el usuario las cambia, las OTP son dinámicas y expiran rápidamente después de su emisión, generalmente en pocos minutos. Esta naturaleza dinámica hace que las OTP sean significativamente más seguras porque reducen enormemente el riesgo de acceso no autorizado incluso si la OTP es interceptada por partes malintencionadas.
Las OTP generalmente se generan utilizando algoritmos basados en sincronización de tiempo o cálculos matemáticos, asegurando que cada código sea único e impredecible. Los usuarios suelen recibir las OTP a través de SMS, correo electrónico, aplicaciones móviles o tokens de hardware.
¿Cuáles son los casos de uso comunes de OTP (contraseña de un solo uso)?
Aquí están algunos de los usos principales de las OTP:
Inicio de sesión sin contraseña
Muchos sitios web y aplicaciones ahora ofrecen opciones de inicio de sesión sin contraseña para mejorar la seguridad y la conveniencia del usuario. Los usuarios pueden solicitar una OTP enviada a su número de móvil o correo electrónico registrado para autenticar su identidad, sin necesidad de recordar contraseñas complejas. Este enfoque no solo simplifica el proceso de inicio de sesión, sino que también reduce el riesgo de brechas relacionadas con contraseñas.
Recuperación de contraseñas
En casos donde los usuarios olvidan sus contraseñas, las OTP sirven como un método seguro para la recuperación de cuentas. Los usuarios pueden solicitar una OTP, que se envía a su correo electrónico o número de teléfono registrado, para verificar su identidad antes de restablecer su contraseña. Este proceso ayuda a garantizar que solo el propietario legítimo de la cuenta pueda realizar la recuperación.
Autenticación multifactor (MFA)
Las OTP son un componente vital de la Autenticación Multifactor (MFA), que combina algo que el usuario sabe (como una contraseña) con algo que el usuario tiene (como un dispositivo móvil). Después de ingresar su contraseña principal, los usuarios reciben una OTP que deben ingresar para obtener acceso. Esta capa adicional de seguridad reduce significativamente la probabilidad de acceso no autorizado, incluso si la contraseña principal se ve comprometida.
Confirmación de transacciones sensibles
Para actividades que involucran datos sensibles o transacciones significativas, como la banca en línea o la realización de compras de alto valor, las OTP sirven como medida de seguridad para confirmar el consentimiento del usuario. Antes de completar estas acciones, se envía una OTP al método de contacto registrado del usuario, que debe ingresarse para finalizar la transacción. Esto asegura que, incluso si alguien obtiene acceso a la cuenta del usuario, no pueda realizar acciones críticas sin la OTP.
Contraseña de un solo uso basada en el tiempo (Time-based one-time password, TOTP)
Una contraseña de un solo uso basada en el tiempo (TOTP) es un código temporal y único generado por un algoritmo que utiliza el tiempo actual como un factor clave.
¿Qué es TOTP?
Una Contraseña de un Solo Uso Basada en el Tiempo (TOTP) es un código temporal y único generado por un algoritmo que utiliza el tiempo actual como un factor clave. Similar a un Contraseña de un solo uso (One-time password, OTP) genérico, un TOTP se usa solo una vez, pero tiene una vida útil fija, que generalmente varía entre 30 y 60 segundos. Al expirar, se genera automáticamente un nuevo código.
El estándar TOTP está definido por el Internet Engineering Task Force (IETF) bajo RFC 6238 y es ampliamente adoptado en varios sistemas de autenticación de dos factores (2FA) y autenticación multifactor (MFA). Debido a que los TOTP dependen de una sincronización temporal entre el cliente (dispositivo del usuario) y el servidor, ofrecen un alto nivel de seguridad y son difíciles de predecir o reutilizar.
Cómo funciona TOTP
La generación de un TOTP involucra los siguientes pasos:
- Clave secreta compartida: Durante la configuración inicial, se genera una clave secreta compartida que se almacena de manera segura tanto en el cliente como en el servidor. Esta clave suele estar codificada como un código QR que los usuarios escanean utilizando una aplicación de autenticación.
- Intervalos de tiempo: El tiempo actual se divide en intervalos fijos, usualmente de 30 segundos.
- Aplicación de algoritmo: La clave secreta compartida y la marca de tiempo actual se introducen en un algoritmo basado en hash (a menudo HMAC-SHA1) para producir un código numérico único.
- Sincronización: Tanto el cliente como el servidor generan el código de manera independiente utilizando la misma clave secreta compartida y la marca de tiempo actual. Los códigos coinciden solo si ambos están sincronizados.
- Verificación: Cuando el usuario inicia sesión o realiza una transacción crítica, ingresa el TOTP mostrado en su aplicación de autenticación. El servidor luego lo compara con su TOTP generado internamente para validación.
Cuándo usar TOTP
En la mayoría de los casos, se recomienda un OTP normal, pero en los casos donde no se puede “activar” un código nuevo, entonces se recomienda TOTP.
- Ejemplo de TOTP: App Authenticator
- Ejemplo de OTP: Email, SMS
¿Cuál es la diferencia entre OTP y TOTP?
La principal diferencia es que TOTP está basado en el tiempo, por lo que es adecuado cuando el dispositivo no está conectado al servidor. El servidor puede fácilmente enviar un nuevo código a una dirección de correo electrónico o a un número de teléfono, pero eso requiere que el correo o teléfono esté en línea. Sin embargo, la App Authenticator puede permanecer desconectada y usar el “tiempo” para verificar el código.
Control de acceso (Access control)
El control de acceso es la restricción de quién puede realizar qué acciones sobre ciertos recursos en un sistema. Es un mecanismo de seguridad fundamental para definir y hacer cumplir políticas de acceso.
¿Qué es el control de acceso (Access control)?
El control de acceso (Access control) involucra tres componentes principales:
- Sujeto: Una entidad que realiza acciones sobre recursos. Los sujetos pueden ser usuarios, servicios o dispositivos.
- Recurso: Una entidad que está protegida por el control de acceso. Los recursos pueden ser archivos, bases de datos, APIs u otros activos digitales.
- Acción: Una operación que un sujeto puede realizar sobre un recurso. Las acciones pueden ser leer, escribir, ejecutar u cualquier otra operación.
El control de acceso (Access control) define la restricción selectiva de acceso a recursos basada en el sujeto y la acción.
Aquí hay algunos ejemplos del mundo real de control de acceso (Access control):
- Un usuario (sujeto) puede leer (acción) sus pedidos (recurso) en un sistema de comercio electrónico.
- Un usuario (sujeto) no puede eliminar (acción) el perfil de otro usuario (recurso) en una red social.
- Un servicio (sujeto) puede escribir (acción) datos en una base de datos (recurso) en una arquitectura de microservicios.
A veces, el recurso se ignora en implementaciones técnicas y el control de acceso (Access control) se define como la restricción de quién (sujeto) puede realizar qué acciones. Por ejemplo, el marco básico de OAuth 2.0 solo especifica acciones utilizando scopes (permisos) y no define recursos.
El soporte para el control de acceso (Access control) puede variar dependiendo del Servidor de autorización (Authorization server) o el Proveedor de identidad (Identity provider, IdP) . Algunos sistemas pueden soportar Resource Indicators for OAuth 2.0, una extensión de OAuth 2.0 que permite a los clientes especificar los recursos a los que desean acceder.
Modelos de control de acceso (Access control)
Decidir restricciones entre unos pocos sujetos y recursos es simple, pero no escalable. Por lo tanto, la industria ha desarrollado muchos modelos de control de acceso (Access control) para gestionarlo de manera efectiva. En el contexto de Gestión de identidades y access (Identity and access management, IAM) , los siguientes son algunos modelos comunes de control de acceso (Access control):
- Control de acceso basado en roles (Role-based access control, RBAC): Un modelo que asigna permisos a roles y luego asigna roles a sujetos. Por ejemplo, un rol de administrador podría tener acceso a todos los recursos, mientras que un rol de usuario podría tener acceso a recursos limitados.
- Control de acceso basado en atributos (Attribute-based access control, ABAC): Un modelo que utiliza atributos (propiedades) del sujeto, recurso y entorno para tomar decisiones de control de acceso (Access control). Por ejemplo, un usuario con el atributo “departamento=ingeniería” podría tener acceso a recursos de ingeniería.
También existen otros modelos de control de acceso (Access control) como control de acceso basado en políticas (PBAC) . Cada modelo tiene sus propias fortalezas y debilidades, y la elección del modelo depende de tu caso de uso y requisitos.
Control de acceso (Access control) en OAuth 2.0
En el contexto de OAuth 2.0, el control de acceso (Access control) se implementa típicamente usando scopes . Normalmente, el valor de un scope es una cadena que combina el recurso y la acción. Por ejemplo, read:orderso write:profile.
[!Note] El término “scopes” es intercambiable con “permissions” en la mayoría de los casos.
Vale la pena destacar que OAuth 2.0 no define la estructura y el significado de los scopes. La interpretación de los scopes se deja al Servidor de recursos (Resource server) , y la emisión de scopes se deja al Servidor de autorización (Authorization server) .
Por ejemplo, un usuario (sujeto) necesita acceder a sus pedidos (recurso) en un sistema de comercio electrónico. Al aprovechar OAuth 2.0, puedes definir un scope read:orders y una aplicación web (cliente) solicitará este scope desde el servidor de autorización. Aquí hay un flujo simplificado:
En este flujo, dependiendo de la arquitectura técnica, el servidor de recursos puede ser un servicio API o puede ser el cliente (aplicación web) en sí, siempre y cuando tenga la capacidad de acceder al recurso (pedidos).
El parámetro de indicador de recurso (resource indicator)
Aunque las personas a menudo definen scopes con recurso y acción (por ejemplo, read:orders, donde orders es el recurso y read es la acción), la escalabilidad de este enfoque es limitada cuando la cantidad de recursos y acciones crece. RFC 8707 introduce el parámetro resource (es decir, indicadores de recurso ) a OAuth 2.0, lo que permite a los clientes especificar los recursos a los que desean acceder.
El RFC especifica que el parámetro resource debe ser un URI que represente el recurso. Por ejemplo, en lugar de simplemente usar orders, podrías usar https://api.example.com/orders. Este método ayuda a evitar conflictos de nombres y mejora la precisión de la coincidencia de recursos al permitir el uso de la URL real del recurso.
Soporte del servidor de autorización (authorization server)
OAuth 2.0 no define cómo debe llevar a cabo el control de acceso (Access control) el servidor de autorización (authorization server). Deja los detalles de implementación a discreción del servidor de autorización (authorization server). Por lo tanto, la elección del servidor de autorización puede afectar en gran medida el mecanismo de control de acceso (Access control). Por ejemplo, algunos servidores de autorización pueden soportar indicadores de recurso, mientras que otros no. Es importante decidir qué modelo de control de acceso (Access control) utilizar en función de tus requisitos empresariales y luego elegir un servidor de autorización que soporte ese modelo. Si no estás seguro sobre el modelo de control de acceso (Access control), Control de acceso basado en roles (Role-based access control, RBAC) es suficiente para la mayoría de los casos.
Control de acceso basado en atributos (Attribute-based access control, ABAC)
El control de acceso basado en atributos (ABAC) es un modelo de control de acceso que utiliza atributos (como roles de usuario, propiedades de recursos y condiciones ambientales) para tomar decisiones de control de acceso. Es una forma flexible y dinámica de gestionar el acceso a recursos protegidos.
¿Qué es el control de acceso basado en atributos (ABAC)?
ABAC es un modelo de Control de acceso (Access control) que utiliza atributos para tomar decisiones de control de acceso. Estos atributos pueden incluir varios factores, como:
- Atributos de usuario: por ejemplo, roles, departamento, ubicación, etc.
- Atributos de recursos: por ejemplo, nivel de sensibilidad, propietario, tipo, etc.
- Atributos ambientales: por ejemplo, hora de acceso, ubicación, dispositivo, etc.
Al evaluar estos atributos y ejecutarlos a través de un conjunto de reglas, ABAC puede determinar si un sujeto (por ejemplo, usuario, servicio) debe tener acceso a un recurso. Este enfoque permite un control de acceso detallado y una aplicación dinámica de políticas basadas en el contexto.
¿Cómo funciona el ABAC?
ABAC utiliza un enfoque basado en políticas para el control de acceso. Una política ABAC típica consta de:
- Subject: La entidad que solicita acceso (por ejemplo, usuario, servicio, dispositivo).
- Action: La operación que se realiza en el recurso (por ejemplo, leer, escribir, eliminar).
- Resource: La entidad a la que se accede (por ejemplo, archivo, base de datos, API).
- Environment: El contexto en el que se solicita el acceso (por ejemplo, hora, ubicación, dispositivo).
- Attributes: Las propiedades del sujeto, recurso y entorno que se evalúan para tomar decisiones de acceso.
- Policies: Un conjunto de reglas que definen las condiciones bajo las cuales se concede o se niega el acceso.
Las políticas ABAC son más complejas que los modelos de control de acceso tradicionales como Control de acceso basado en roles (Role-based access control, RBAC) . Por otro lado, ABAC proporciona más flexibilidad y granularidad en las decisiones de control de acceso.
Ejemplo de políticas ABAC
Por ejemplo, un sistema tiene varias políticas ABAC:
-
Política 1: Permitir el acceso si:
- (Subject) El rol del sujeto es
manager. - (Attribute) El nivel de sensibilidad del recurso es
high. - (Environment) La ubicación es
internal. - (Action) Cualquier acción.
- (Environment) El tiempo es entre las 9 AM y las 5 PM (horas de oficina).
- (Subject) El rol del sujeto es
-
Política 2: Denegar el acceso si:
- (Subject) El rol del sujeto no es
manager. - (Attribute) El nivel de sensibilidad del recurso es
high. - (Environment) Cualquier ubicación.
- (Action) Cualquier acción.
- (Environment) Cualquier momento.
- (Subject) El rol del sujeto no es
-
Política 3: Permitir el acceso si:
- (Subject) El rol del sujeto es
employeeomanager. - (Attribute) El nivel de sensibilidad del recurso es
low. - (Environment) Cualquier ubicación.
- (Action) Acción
read. - (Environment) Cualquier momento.
- (Subject) El rol del sujeto es
El motor de evaluación de políticas verificará estas políticas en orden, y la primera política que coincida con las condiciones determinará la decisión de acceso. Mientras tanto, se aplica una política de denegación predeterminada si ninguna otra política coincide.
Veamos algunos escenarios para entender cómo funciona el ABAC:
Escenario 1. Un usuario quiere acceder (realizar la acción
read) a un documento de alto nivel de sensibilidad (recurso) fuera de la oficina (entorno). El usuario tiene el rol demanageralmacenado en el sistema.
Decisión: El acceso se niega porque el usuario está fuera de la oficina (la ubicación no es internal).
Escenario 2. Un usuario quiere acceder (realizar la acción
read) a un documento de alto nivel de sensibilidad (recurso) durante las horas de oficina (entorno) en la red de la oficina (ubicación=internal). El usuario tiene el rol demanager.
Decisión: El acceso se concede porque se cumplen todas las condiciones de la Política 1.
Escenario 3. Todas las condiciones en el escenario 2 son las mismas, pero el usuario tiene el rol de
employeeen lugar demanager.
Decisión: El acceso se niega porque el rol del usuario no coincide con las condiciones de la Política 1.
Escenario 4. Un usuario quiere acceder (realizar la acción
read) a un documento de bajo nivel de sensibilidad (recurso). El usuario tiene el rol deemployee.
Decisión: El acceso se concede porque se cumplen todas las condiciones de la Política 3.
Escenario 5. Un usuario quiere eliminar (realizar la acción
delete) un documento de bajo nivel de sensibilidad (recurso). El usuario tiene el rol deemployee.
Decisión: El acceso se niega porque no hay ninguna política que permita la acción delete en documentos de bajo nivel de sensibilidad.
Podrás notar que no se requieren todos los atributos en cada política. Esta flexibilidad permite un mecanismo de control de acceso más dinámico y consciente del contexto.
Lenguaje Extensible de Control de Acceso (XACML)
XACML es un estándar basado en XML para expresar políticas de control de acceso. Aunque no define un modelo específico de control de acceso, XACML se utiliza a menudo para implementar políticas ABAC. Veamos un ejemplo no normativo de cómo se puede usar XACML para representar las políticas ABAC del ejemplo anterior:
<PolicySet PolicySetId="ABAC_Policies" PolicyCombiningAlgId="urn:oasis:names:tc:xacml:3.0:policy-combining-algorithm:deny-overrides">
<Description>ABAC Policies</Description>
<Policy PolicyId="Policy1" RuleCombiningAlgId="urn:oasis:names:tc:xacml:3.0:rule-combining-algorithm:deny-overrides">
<Description>Employees can read data</Description>
<Target>
<AnyOf>
<AllOf>
<Match MatchId="urn:oasis:names:tc:xacml:1.0:function:string-equal">
<AttributeValue DataType="http://www.w3.org/2001/XMLSchema#string">read</AttributeValue>
<AttributeDesignator
AttributeId="urn:oasis:names:tc:xacml:1.0:action:action-id"
Category="urn:oasis:names:tc:xacml:3.0:attribute-category:action"
DataType="http://www.w3.org/2001/XMLSchema#string"
MustBePresent="true"
/>
</Match>
</AllOf>
</AnyOf>
</Target>
<Rule RuleId="Rule1" Effect="Permit">
<Target>
<AnyOf>
<AllOf>
<Match MatchId="urn:oasis:names:tc:xacml:1.0:function:string-equal">
<AttributeValue DataType="http://www.w3.org/2001/XMLSchema#string">employee</AttributeValue>
<AttributeDesignator
AttributeId="urn:oasis:names:tc:xacml:1.0:subject:subject-id"
Category="urn:oasis:names:tc:xacml:1.0:subject-category:access-subject"
DataType="http://www.w3.org/2001/XMLSchema#string"
MustBePresent="true"
/>
</Match>
</AllOf>
</AnyOf>
</Target>
</Rule>
<Rule RuleId="Rule2" Effect="Deny">
<Target>
<AnyOf>
<AllOf>
<Match MatchId="urn:oasis:names:tc:xacml:1.0:function:string-equal">
<AttributeValue DataType="http://www.w3.org/2001/XMLSchema#string">user</AttributeValue>
<AttributeDesignator
AttributeId="urn:oasis:names:tc:xacml:1.0:subject:subject-id"
Category="urn:oasis:names:tc:xacml:1.0:subject-category:access-subject"
DataType="http://www.w3.org/2001/XMLSchema#string"
MustBePresent="true"
/>
</Match>
</AllOf>
</AnyOf>
</Target>
</Rule>
</Policy>
<!-- ...other policies... -->
</PolicySet>
Consideraciones de implementación
Si bien el ABAC ofrece una forma poderosa de gestionar el control de acceso, también presenta algunas consideraciones de implementación:
- Complejidad del sistema: Las políticas ABAC pueden volverse complejas a medida que aumenta el número de atributos y reglas. La gestión y prueba adecuada de políticas son más laboriosas que los modelos de control de acceso más simples.
- Rendimiento: Evaluar políticas ABAC complejas puede afectar el rendimiento del sistema. Las técnicas de almacenamiento en caché y optimización pueden ayudar a mitigar este problema.
- Conflictos de políticas: Las políticas en conflicto pueden llevar a decisiones de acceso impredecibles. La revisión periódica de políticas y la resolución de conflictos deben ser parte del proceso de gestión de políticas.
ABAC vs. RBAC
Comparar ABAC con Control de acceso basado en roles (Role-based access control, RBAC) puede ayudarte a comprender las diferencias entre los dos modelos:
| RBAC | ABAC | |
|---|---|---|
| Política de control de acceso | Basada en roles | Basada en atributos |
| Granularidad | Gruesa | Fina |
| Flexibilidad | Limitada | Muy flexible |
| Complejidad | Más simple | Más compleja |
| Impacto en el rendimiento | Mínimo | Puede ser significativo |
| Gestión de acceso | Gestión de roles | Gestión de políticas |
| Mejor para | Estructuras de permisos bien definidas | Control de acceso dinámico y consciente del contexto |
Control de acceso basado en roles (Role-based access control, RBAC)
El control de acceso basado en roles (RBAC) es un modelo de control de acceso que asigna permisos a roles en lugar de directamente a usuarios, proporcionando una forma flexible y eficiente de gestionar los derechos de acceso en los sistemas.
¿Qué es el control de acceso basado en roles (RBAC)?
El control de acceso basado en roles (RBAC) es un modelo de control de acceso adoptado ampliamente que introduce el concepto de “roles” para desacoplar usuarios de permisos, resultando en un sistema de gestión de permisos flexible y eficiente.
La idea central detrás de RBAC es simple pero poderosa: en lugar de asignar permisos directamente a los usuarios, los permisos se asignan a roles, que luego se asignan a los usuarios. Este método indirecto de asignación de permisos simplifica en gran medida el proceso de gestión de derechos de acceso.
Conceptos clave en RBAC
El modelo RBAC gira en torno a cuatro elementos principales:
- Usuarios: Individuos dentro del sistema, típicamente personas reales.
- Roles: Representaciones de funciones laborales o responsabilidades dentro de una organización.
- Permisos: Autorizaciones para realizar operaciones específicas en recursos particulares.
- Sesiones: Entornos dinámicos donde los usuarios activan ciertos roles.
El flujo de trabajo básico de RBAC se puede resumir de la siguiente manera:
- Definir roles basados en la estructura organizacional o los requisitos comerciales.
- Asignar permisos apropiados a cada rol.
- Asignar uno o más roles a los usuarios según sus responsabilidades.
- Cuando un usuario intenta acceder a un recurso, el sistema verifica si los roles asignados tienen los permisos necesarios.
Tipos de RBAC
RBAC0: La fundación
RBAC0 es el modelo básico que define los conceptos centrales de usuarios, roles, permisos y sesiones. Sirve como la base para todos los demás modelos RBAC.
Características clave:
- Asociación usuario-rol: Relación de muchos a muchos
- Asociación rol-permiso: Relación de muchos a muchos
Este diagrama ilustra la estructura básica de RBAC0, mostrando las relaciones entre usuarios, roles y permisos.
Operaciones clave:
- Asignación de roles a usuarios
- Asignación de permisos a roles
- Comprobación de si un usuario tiene un permiso específico
Aunque RBAC0 proporciona un punto de partida sólido, tiene algunas limitaciones:
- Explosión de roles: A medida que aumenta la complejidad del sistema, el número de roles puede crecer rápidamente.
- Redundancia de permisos: Diferentes roles pueden requerir conjuntos similares de permisos, llevando a la duplicación.
- Falta de jerarquía: No puede representar relaciones de herencia entre roles.
RBAC1: Introduciendo jerarquías de roles
RBAC1 se construye sobre RBAC0 al agregar el concepto de herencia de roles.
RBAC1 = RBAC0 + Herencia de Roles
Características clave:
- Jerarquía de roles: Los roles pueden tener roles padres
- Herencia de permisos: Los roles hijos heredan todos los permisos de sus roles padres
Este diagrama muestra cómo los roles pueden heredar de otros roles en RBAC1.
Operaciones clave:
Este diagrama de flujo ilustra el proceso de asignación de roles y verificación de permisos en RBAC1, incluyendo el aspecto de herencia de roles.
RBAC1 ofrece varias ventajas:
- Número reducido de roles: Se pueden crear menos roles base a través de la herencia.
- Gestión simplificada de permisos: Más fácil reflejar jerarquías organizacionales.
Sin embargo, RBAC1 aún tiene algunas limitaciones:
- Falta de mecanismos de restricción: Incapaz de restringir a los usuarios de tener simultáneamente roles potencialmente conflictivos.
- Consideraciones de rendimiento: Las verificaciones de permisos pueden requerir recorrer toda la jerarquía de roles.
RBAC2: Implementación de restricciones
RBAC2 también se basa en RBAC0, pero introduce el concepto de restricciones.
RBAC2 = RBAC0 + Restricciones
Características clave:
- Roles mutuamente exclusivos: Los usuarios no pueden ser asignados a estos roles simultáneamente.
- Cardinalidad de roles: Limita el número de usuarios que pueden ser asignados a un rol particular.
- Roles prerrequisito: Los usuarios deben tener un rol específico antes de ser asignados a otro.
Este diagrama de flujo demuestra el proceso de asignación de roles y control de acceso en RBAC2, incorporando las varias restricciones.
RBAC2 mejora la seguridad al prevenir la concentración excesiva de permisos y permite un control de acceso más preciso. Sin embargo, aumenta la complejidad del sistema y puede impactar el rendimiento debido a la necesidad de verificar múltiples condiciones de restricción para cada asignación de rol.
RBAC3: El modelo integral
RBAC3 combina las características de RBAC1 y RBAC2, ofreciendo tanto herencia de roles como mecanismos de restricción:
RBAC3 = RBAC0 + Herencia de Roles + Restricciones
Este modelo integral proporciona máxima flexibilidad pero también presenta desafíos en la implementación y optimización del rendimiento.
¿Cuáles son las ventajas de RBAC (control de acceso basado en roles)?
- Gestión simplificada de permisos: La autorización masiva a través de roles reduce la complejidad de gestionar los permisos de usuarios individuales.
- Seguridad mejorada: Un control más preciso sobre los permisos de los usuarios reduce los riesgos de seguridad.
- Costos administrativos reducidos: Modificar los permisos de roles afecta automáticamente a todos los usuarios asociados.
- Alineación con la lógica empresarial: Los roles a menudo corresponden a estructuras organizacionales o procesos de negocios, lo que los hace más fáciles de entender y gestionar.
- Soporte para separación de deberes: Las responsabilidades críticas pueden ser separadas a través de restricciones como roles mutuamente exclusivos.
¿Cuáles son las consideraciones prácticas de implementación?
Al implementar RBAC en escenarios del mundo real, los desarrolladores deberían considerar estos aspectos clave:
- Diseño de bases de datos: Utilizar bases de datos relacionales para almacenar y consultar efectivamente las estructuras de RBAC.
- Optimización del rendimiento: Implementar estrategias de almacenamiento en caché y optimizar las verificaciones de permisos, especialmente para modelos complejos de RBAC3.
- Integración de API y frontend: Diseñar API claras para gestionar usuarios, roles y permisos, y considerar cómo usar RBAC en aplicaciones frontend.
- Seguridad y auditoría: Asegurar la seguridad del sistema RBAC en sí mismo e implementar funciones detalladas de registro y auditoría.
- Escalabilidad: Diseñar pensando en futuras expansiones, como soportar reglas de permiso más complejas o integrarse con otros sistemas.
- Experiencia del usuario: Diseñar interfaces intuitivas para que los administradores del sistema puedan configurar y mantener fácilmente la estructura RBAC.